
L’IA, et plus particulièrement l’IA générative, a le potentiel de transformer les soins de santé.
C’est du moins l’argument de vente d’Hippocratic AI, qui est sortie de la clandestinité aujourd’hui avec un énorme financement d’amorçage de 50 millions de dollars et une évaluation à trois chiffres. La tranche, codirigée par Général Catalyseur et Andreessen Horowitz, est un grand vote de confiance dans la technologie d’Hippocratic, un modèle de génération de texte spécialement conçu pour les applications dans le domaine de la santé.
Hippocratic – issue de General Catalyst – a été fondée par un groupe de médecins, d’administrateurs d’hôpitaux, de professionnels de l’assurance maladie et de chercheurs en intelligence artificielle issus d’organisations telles que Johns Hopkins, Stanford, Google et Nvidia. Après que le cofondateur et PDG Munjal Shah a vendu sa précédente entreprise, Like.com, un site de comparaison d’achats, à Google en 2010, il a passé la majeure partie de la décennie suivante à construire Hippocratic.
« Hippocratic a créé le premier grand modèle de langage (LLM) axé sur la sécurité et conçu spécifiquement pour les soins de santé », a déclaré Shah à TechCrunch lors d’une interview par e-mail. « La mission de l’entreprise est de développer le modèle de santé artificiel le plus sûr.eneral afin d’améliorer considérablement l’accessibilité aux soins de santé et les résultats en matière de santé ».
Historiquement, l’IA dans les soins de santé a connu un succès mitigé.
Babylon Health, une start-up spécialisée dans l’IA et soutenue par le Service national de santé du Royaume-Uni, a fait l’objet d’un examen minutieux pour avoir prétendu que sa technologie de diagnostic des maladies était plus performante que celle des médecins. IBM a été contraint de vendre à perte sa division Watson Health, axée sur l’IA, après que des problèmes techniques ont entraîné la détérioration de partenariats avec d’importants clients. Par ailleurs, GPT-3 d’OpenAI, le prédécesseur de GPT-4, a incité au moins un utilisateur à se suicider.
M. Shah a souligné qu’Hippocratic n’était pas axé sur le diagnostic. La technologie – qui est orientée vers le consommateur – vise plutôt des cas d’utilisation tels que l’explication des avantages et de la facturation, la fourniture de conseils diététiques et de rappels de médicaments, la réponse aux questions préopératoires, l’intégration des patients et la fourniture de résultats de tests « négatifs » qui indiquent qu’il n’y a rien d’anormal.
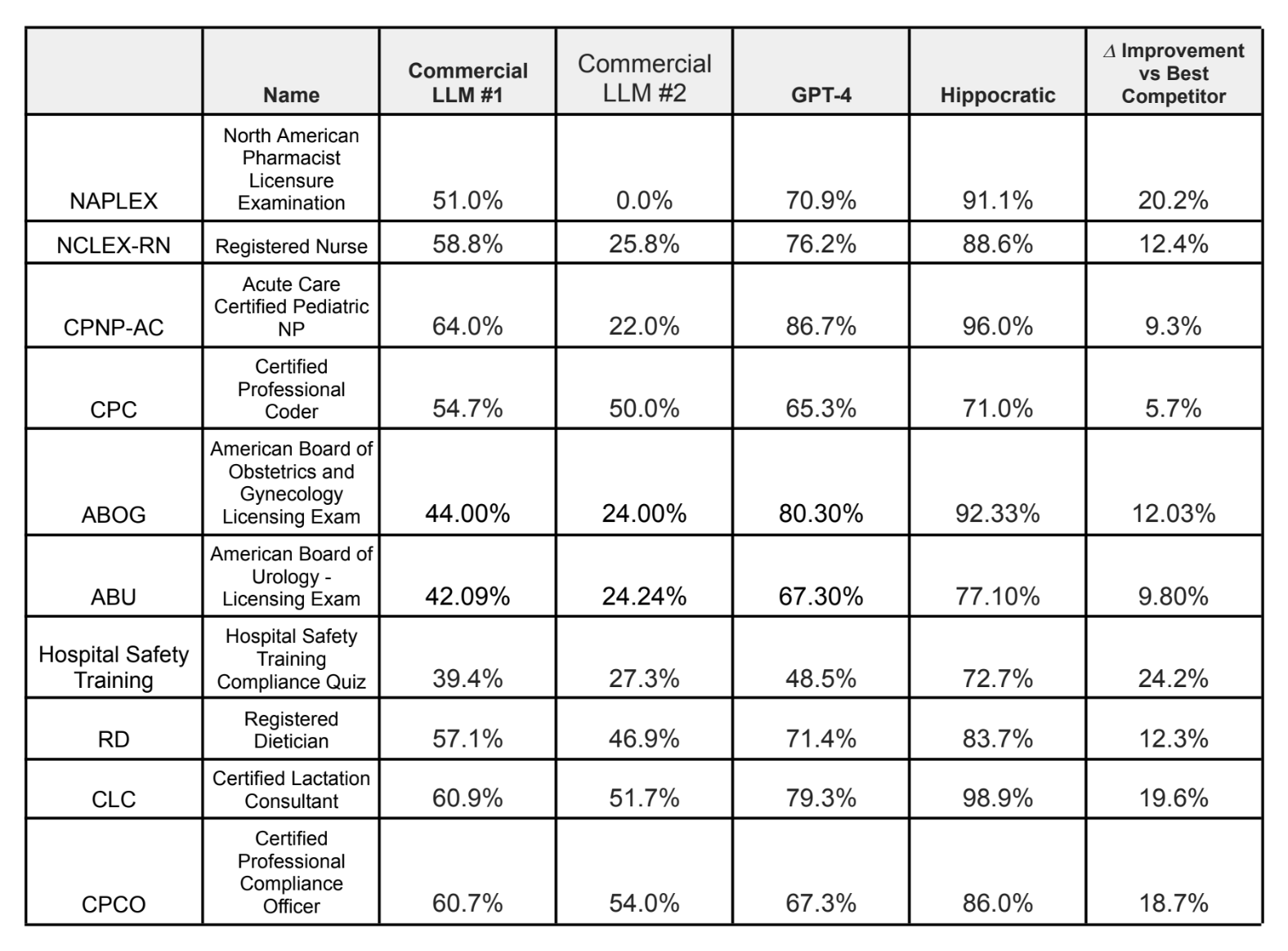
Les résultats de référence d’Hippocratic sur une série d’examens médicaux.
Le cas d’utilisation des conseils diététiques m’a fait réfléchir, je dois dire, à la lumière des suggestions médiocres que l’IA, comme ChatGPT d’OpenAI, fournit en matière de régime alimentaire. Mais Shah affirme que l’IA d’Hippocratic surpasse les principaux modèles de langage, dont GPT-4 et Claude, sur plus de 100 certifications médicales, dont le NCLEX-RN pour les infirmières, l’examen de l’American Board of Urology et l’examen de diététicien agréé.
« Les modèles linguistiques doivent être sûrs », a déclaré M. Shah. « C’est pourquoi nous construisons un modèle uniquement axé sur la sécurité, que nous faisons certifier par des professionnels de la santé et que nous travaillons en étroite collaboration avec le secteur… Cela permettra de garantir que les politiques de conservation des données et de protection de la vie privée seront conformes aux normes actuelles du secteur de la santé. »
L’un des moyens utilisés par Hippocratic pour atteindre cet objectif est de « détecter le ton » et de « communiquer l’empathie » mieux que les technologies concurrentes, explique M. Shah – en partie en « intégrant » un bon comportement au chevet du patient (c’est-à-dire l’insaisissable « toucher humain »). Il affirme que les comportements au chevet des patients – en particulier les interactions qui laissent aux patients un sentiment d’espoir, même dans des circonstances sombres – peuvent avoir et ont un effet sur les résultats en matière de santé.
Pour évaluer le comportement au chevet du patient, Hippocratic a conçu un test permettant de vérifier les signes d’humanisme du modèle, comme « faire preuve d’empathie » et « s’intéresser personnellement à la vie du patient ». (La question de savoir si un seul test peut rendre compte avec précision de sujets aussi nuancés est bien entendu sujette à débat). Sans surprise, compte tenu de la source, le modèle d’Hippocratic a obtenu les meilleurs résultats dans toutes les catégories des modèles testés par Hippocratic, y compris le GPT-4.
Mais un modèle linguistique peut-il vraiment remplacer un professionnel de la santé ? Hippocratic pose la question, arguant que ses modèles ont été formés sous la supervision de professionnels de la santé et qu’ils sont donc très compétents.
« Nous ne diffusons chaque rôle – diététicien, agent de facturation, conseiller génétique, etc. – qu’une fois que les personnes qui exercent ce rôle aujourd’hui dans la vie réelle sont d’accord pour dire que le modèle est prêt », a déclaré M. Shah. « Lors de la pandémie, les coûts de main-d’œuvre ont augmenté de 30 % pour la plupart des systèmes de santé, mais pas les recettes. C’est pourquoi la plupart des systèmes de santé du pays sont en difficulté financière. Les modèles linguistiques peuvent les aider à réduire les coûts en pourvoyant les nombreux postes vacants de manière plus rentable.
Je ne suis pas sûr que les professionnels de la santé soient d’accord, surtout si l’on considère les faibles scores du modèle Hippocratic dans certaines des certifications susmentionnées. Selon Hippocratic, le modèle a obtenu 71 % à l’examen de codeur professionnel certifié, qui couvre les connaissances en matière de facturation et de codage médicaux, et 72,7 % au test de conformité de la formation à la sécurité hospitalière.
Il y a aussi la question de la partialité potentielle. Le secteur des soins de santé est entaché de biais, et ces effets se répercutent sur les modèles formés à partir de dossiers médicaux, d’études et de recherches biaisés. Une étude réalisée en 2019, par exemple, a révélé qu’un algorithme utilisé par de nombreux hôpitaux pour déterminer quels patients avaient besoin de soins traitait les patients noirs avec moins de sensibilité que les patients blancs.
En tout état de cause, on peut espérer qu’Hippocratic précise que ses modèles ne sont pas infaillibles. Dans des domaines tels que les soins de santé, le biais d’automatisation, ou la propension des gens à faire confiance à l’IA plutôt qu’à d’autres sources, même si elles sont correctes, comporte des risques manifestement élevés.
Ces détails font partie des nombreuses questions qu’Hippocratic doit encore régler. L’entreprise ne divulgue pas de détails sur ses partenaires ou ses clients, préférant se concentrer sur le financement. Le modèle n’est même pas disponible à l’heure actuelle, pas plus que les données sur lesquelles il a été formé ou celles sur lesquelles il pourrait être formé à l’avenir. (Hippocratic se contente de dire qu’elle utilisera des données « dépersonnalisées » pour la formation au modèle).
S’il attend trop longtemps, Hippocratic risque de se laisser distancer par des concurrents tels que Truveta et Latent, dont certains disposent d’un avantage considérable en termes de ressources. Par exemple, Google a récemment commencé à présenter en avant-première Med-PaLM 2, qui, selon lui, a été le premier modèle linguistique à donner des résultats de niveau expert sur des dizaines de questions d’examen médical. Comme le modèle d’Hippocratic, Med-PaLM 2 a été évalué par des professionnels de la santé sur sa capacité à répondre avec précision – et en toute sécurité – à des questions médicales.
Hemant Taneja, directeur général de General Catalyst, n’a pas exprimé d’inquiétude.
« Munjal et moi-même avons créé cette entreprise en partant du principe que les soins de santé ont besoin de leur propre modèle de langage conçu spécifiquement pour les applications de soins de santé – un modèle qui soit juste, impartial, sûr et bénéfique pour la société », a-t-il déclaré par courrier électronique. Nous avons entrepris de créer une application d’IA de haute intégrité, alimentée par un régime de données « sain » et comprenant une approche de formation qui cherche à incorporer un retour d’information humain approfondi de la part d’experts médicaux pour chaque tâche spécialisée. Dans le domaine de la santé, nous ne pouvons tout simplement pas nous permettre d’aller vite et de tout casser ».
M. Shah précise que la majeure partie de la tranche d’amorçage de 50 millions de dollars sera consacrée à l’investissement dans les talents, les données informatiques et les partenariats.