
Pour paraphraser Andreessen Horowitz, l’IA générative, en particulier dans le domaine de la création de textes et d’images, est en train de dévorer le monde. C’est du moins ce que pensent les investisseurs, à en juger par les milliards de dollars qu’ils ont déversés dans des startups développant une IA qui crée des textes et des images à partir de messages-guides.
Pour ne pas être en reste, les grandes entreprises technologiques investissent dans leurs propres solutions artistiques d’IA générative, que ce soit par le biais de partenariats avec les startups susmentionnées ou d’activités de recherche et développement internes. (Voir : Microsoft s’associe à OpenAI pour Image Creator.) Google, tirant parti de son aile robuste de R & D, a décidé de suivre cette dernière voie, en commercialisant son travail en matière d’IA générative pour concurrencer les plates-formes déjà en place.
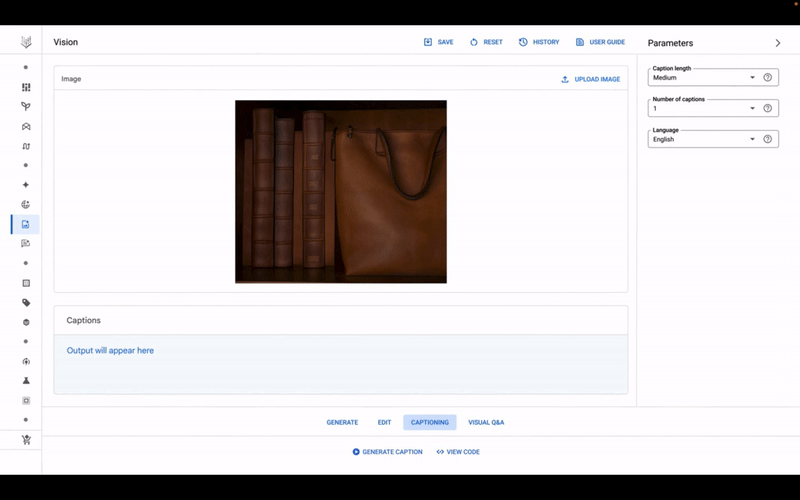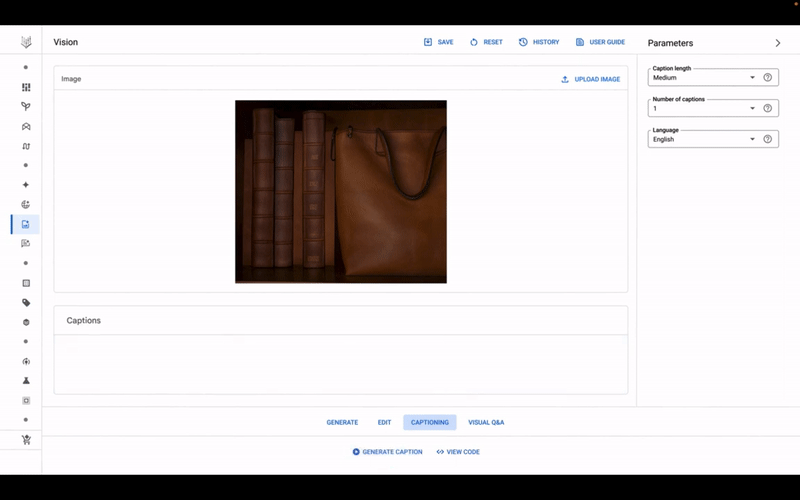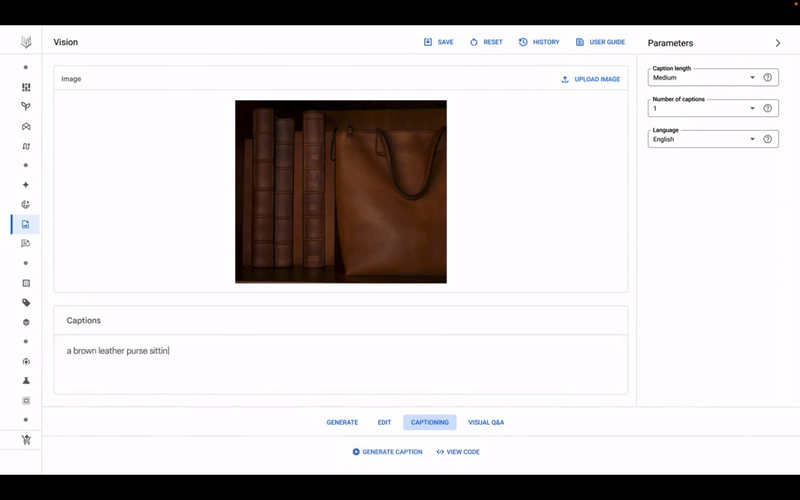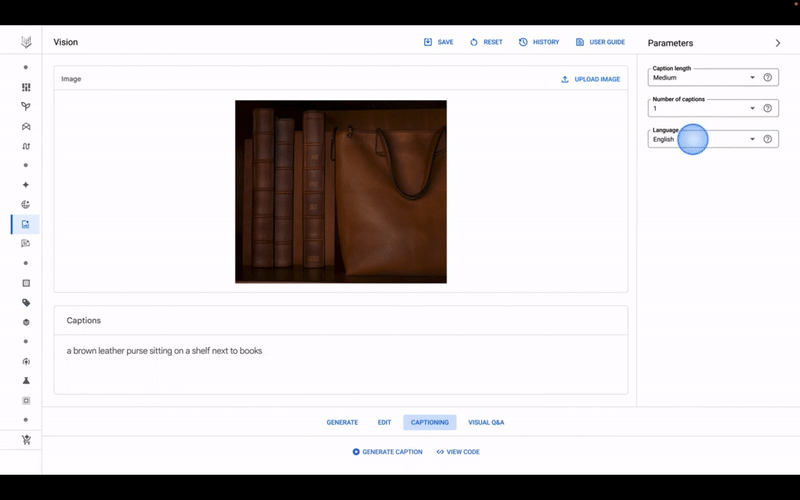
Aujourd’hui, lors de sa conférence annuelle I/O pour les développeurs, Google a annoncé de nouveaux modèles d’IA destinés à Vertex AI, son service d’IA entièrement géré, notamment un modèle de conversion de texte en image appelé Imagen. Imagen, que Google a présenté en avant-première via son application AI Test Kitchen en novembre dernier, peut générer et éditer des images ainsi que rédiger des légendes pour des images existantes.
« Nenshad Bardoliwalla, directeur de Vertex AI chez Google Cloud, a déclaré à TechCrunch lors d’un entretien téléphonique : « N’importe quel développeur peut utiliser cette technologie à l’aide de Google Cloud. « Il n’est pas nécessaire d’être un data scientist ou un développeur.
Image dans Vertex
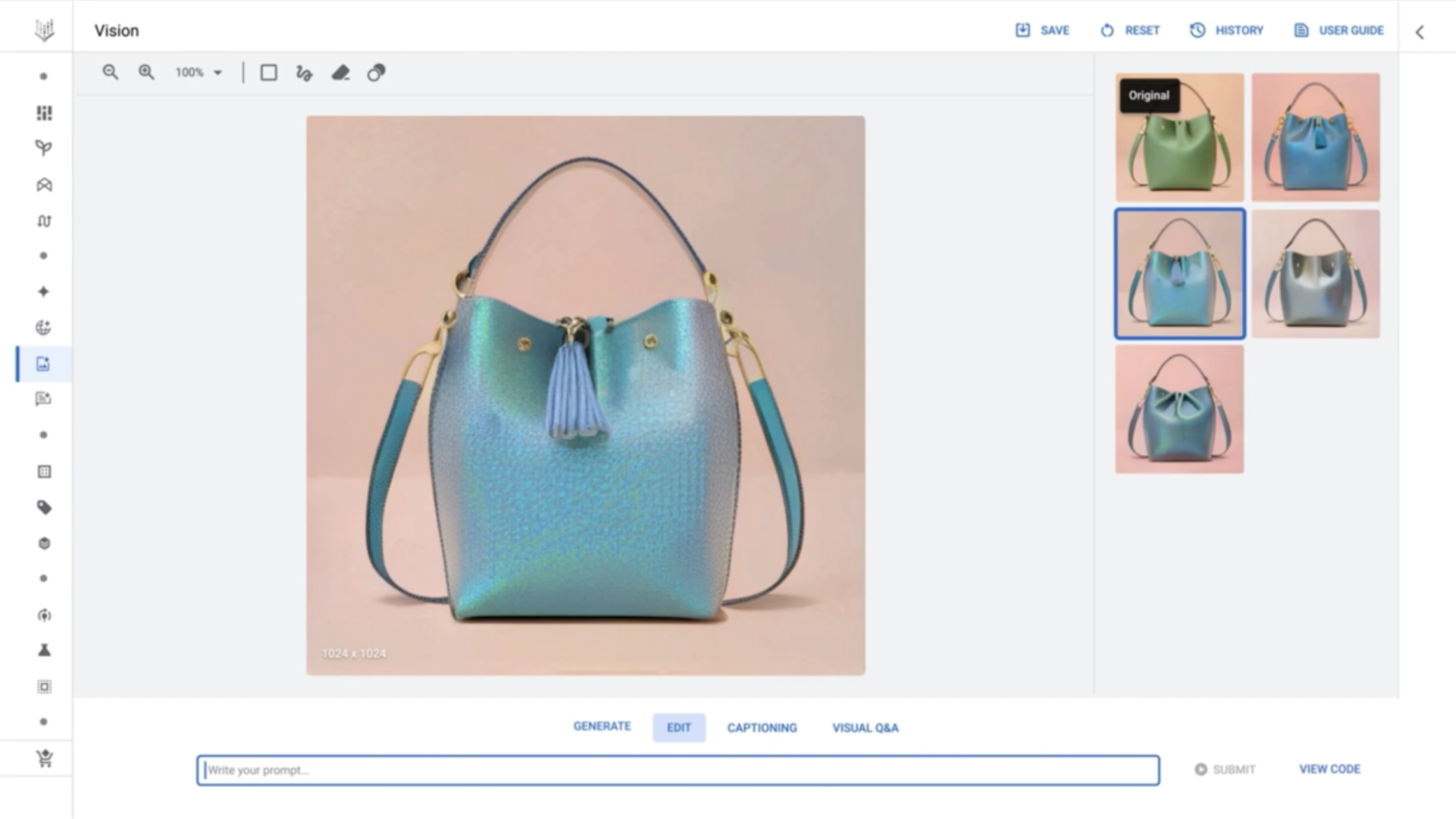
L’utilisation d’Imagen dans Vertex est relativement simple. Une interface utilisateur pour le modèle est accessible à partir de ce que Google appelle le Model Garden, une sélection de modèles développés par Google et de modèles open source. Dans l’interface utilisateur, semblable aux plateformes d’art génératif telles que Midjourney et NightCafe, les clients peuvent saisir des invites (par exemple « un sac à main violet ») pour qu’Imagen génère une poignée d’images candidates.
Des outils d’édition et des messages de suivi permettent d’affiner les images générées par Imagen, par exemple en ajustant la couleur des objets représentés. Vertex propose également une mise à l’échelle pour rendre les images plus nettes, ainsi qu’un réglage fin qui permet aux clients d’orienter Imagen vers certains styles et préférences.
Comme indiqué précédemment, Imagen peut également générer des légendes pour les images, éventuellement traduites à l’aide de Google Translate. Pour se conformer aux règles de confidentialité telles que le GDPR, les images générées qui ne sont pas sauvegardées sont supprimées dans les 24 heures, Bardoliwalla.
« Nous faisons en sorte qu’il soit très facile pour les gens de commencer à travailler avec l’IA générative et leurs images ». a-t-il ajouté.
Bien entendu, toutes les formes d’IA générative posent de nombreux problèmes éthiques et juridiques, quelle que soit la qualité de l’interface utilisateur. Les modèles d’IA comme Imagen « apprennent » à générer des images à partir d’invites textuelles en « s’entraînant » sur des images existantes, qui proviennent souvent d’ensembles de données rassemblées en parcourant des sites web d’hébergement d’images publiques. Certains experts estiment que l’apprentissage de modèles à partir d’images publiques, même protégées par des droits d’auteur, est couvert par la doctrine de l’usage loyal aux États-Unis.

Le modèle Imagen de Google en action, dans Vertex AI. Crédits images : Google
Deux entreprises à l’origine d’outils d’IA artistiques populaires, Midjourney et Stability AI, sont dans le collimateur d’une action en justice qui les accuse d’avoir violé les droits de millions d’artistes en entraînant leurs outils à partir d’images extraites du web. Le fournisseur d’images de stock Getty Images a poursuivi Stability AI en justice, séparément, pour avoir utilisé sans autorisation des millions d’images de son site afin d’entraîner le modèle de génération d’art Stable Diffusion.
J’ai demandé à Bardoliwalla si les clients de Vertex devaient s’inquiéter du fait qu’Imagen ait pu être formé sur des documents protégés par le droit d’auteur. Il est compréhensible qu’ils soient dissuadés de l’utiliser si c’était le cas.
M. Bardoliwalla n’a pas dit d’emblée qu’Imagen n’avait pas été entraîné sur des images protégées par des droits d’auteur, mais seulement que Google procède à de vastes « examens de la gouvernance des données » pour « examiner les données sources » de ses modèles afin de s’assurer qu’elles sont « libres de droits d’auteur ». (Cette formulation n’est pas vraiment surprenante si l’on considère que le modèle original Imagen a été formé sur un ensemble de données publiques, LAION, connu pour contenir des œuvres protégées par le droit d’auteur).
« Nous devons nous assurer que nous respectons toutes les lois relatives aux informations sur les droits d’auteur ». Bardoliwalla. « Nous sommes très clairs avec nos clients : nous leur fournissons des modèles qu’ils peuvent utiliser en toute confiance dans leur travail, et ils sont propriétaires de la propriété intellectuelle générée par les modèles qu’ils ont formés, en toute sécurité.
La propriété intellectuelle est une autre affaire. Aux États-Unis du moins, il n’est pas certain que l’art généré par l’IA soit protégeable par le droit d’auteur.
Une solution – non pas au problème de la propriété en soi, mais aux questions relatives aux données d’apprentissage protégées par le droit d’auteur – consiste à permettre aux artistes de « se retirer » de l’apprentissage de l’IA. La startup Spawning tente d’établir des normes et des outils à l’échelle de l’industrie pour permettre aux artistes de se retirer de la technologie d’IA générative. Adobe cherche à mettre en place ses propres mécanismes et outils d’exclusion. Il en va de même pour DeviantArt, qui a lancé en novembre une protection basée sur des balises HTML afin d’empêcher les robots logiciels d’explorer les pages à la recherche d’images.
Crédits images : Google
Google ne propose pas d’option de désactivation. (Pour être juste, l’un de ses principaux rivaux, OpenAI, ne le fait pas non plus). Bardoliwalla n’a pas dit si cela pourrait changer à l’avenir, mais seulement que Google est « très soucieux » de s’assurer qu’il forme les modèles d’une manière « éthique et responsable ».
C’est un peu fort, je pense, de la part d’une entreprise qui a annulé un comité d’éthique de l’IA externe, qui a expulsé d’éminents chercheurs en éthique de l’IA et qui réduit la publication de recherches sur l’IA pour « faire face à la concurrence et garder le savoir en interne ». Mais interpréter Bardoliwalla comme vous l’entendez.
J’ai également demandé à Bardoliwalla sur les mesures prises par Google, le cas échéant, pour limiter la quantité de contenu toxique ou biaisé créé par Imagen – un autre problème des systèmes d’IA génératifs. Récemment, des chercheurs de la startup Hugging Face et de l’université de Leipzig ont publié un outil démontrant que les modèles tels que Stable Diffusion et DALL-E 2 d’OpenAI ont tendance à produire des images de personnes blanches et masculines, en particulier lorsqu’il s’agit de représenter des personnes en position d’autorité.
Bardoliwalla avait préparé une réponse plus détaillée à cette question, affirmant que chaque appel d’API aux modèles génératifs hébergés par Vertex est évalué pour les « attributs de sécurité », y compris la toxicité, la violence et l’obscénité. Vertex évalue les modèles en fonction de ces attributs et, pour certaines catégories, bloque la réponse ou donne aux clients le choix de la marche à suivre, a expliqué M. Bardoliwalla.
« Nous avons une très bonne idée, grâce à nos propriétés de consommation, du type de contenu qui pourrait ne pas correspondre à ce que nos clients attendent de ces modèles d’IA générative », a déclaré M. Bardoliwalla. poursuit-il. « Cette est un domaine d’investissement important et de leadership sur le marché pour Google – pour nous assurer que nos clients sont en mesure de produire les résultats qu’ils recherchent sans nuire à la valeur de leur marque ».
À cette fin, Google lance l’apprentissage par renforcement à partir de commentaires humains (RLHF) en tant qu’offre de services gérés dans Vertex, qui, selon l’entreprise, aidera les organisations à maintenir les performances des modèles au fil du temps et à déployer des modèles plus sûrs – et nettement plus précis – en production. Le RLHF, une technique populaire dans l’apprentissage automatique, forme un « modèle de récompense » directement à partir du retour d’information humain, par exemple en demandant à des travailleurs contractuels d’évaluer les réponses d’un chatbot d’IA. Elle utilise ensuite ce modèle de récompense pour optimiser un modèle d’IA génératif tel que celui d’Imagen.
Crédits images : Google
Bardoliwalla affirme que la quantité d’ajustements nécessaires par le biais de la RLHF dépendra de l’ampleur du problème que le client tente de résoudre. La question de savoir si la RLHF est toujours la bonne approche fait l’objet d’un débat au sein du monde universitaire. La startup d’IA Anthropic, par exemple, soutient que ce n’est pas le cas, en partie parce que la RLHF peut impliquer l’embauche d’un grand nombre de sous-traitants mal payés qui sont obligés d’évaluer des contenus extrêmement toxiques. Mais Google n’est pas du même avis.
« Avec notre service RLHF, un client peut choisir une modalité et un modèle, puis évaluer les réponses qui proviennent du modèle. Bardoliwalla. « Une fois qu’il soumettent ces réponses au service d’apprentissage par renforcement, le modèle s’adapte pour générer de meilleures réponses qui sont alignées sur … ce que l’organisation recherche ».
Nouveaux modèles et outils
Outre Imagen, plusieurs autres modèles d’IA générative sont désormais disponibles pour certains clients de Vertex, a annoncé Google aujourd’hui : Codey et Chirp.
Codey, la réponse de Google au Copilot de GitHub, peut générer du code dans plus de 20 langages, dont Go, Java, JavaScript, Python et TypeScript. Codey peut suggérer les prochaines lignes en fonction du contexte du code saisi dans une invite ou, comme ChatGPT d’OpenAI, le modèle peut répondre à des questions sur le débogage, la documentation et les concepts de codage de haut niveau.

Crédits images : Google
Quant à Chirp, il s’agit d’un modèle vocal formé sur des « millions » d’heures d’audio qui prend en charge plus de 100 langues et peut être utilisé pour sous-titrer des vidéos, offrir une assistance vocale et, d’une manière générale, exécuter toute une série de tâches et d’applications vocales.
Lors de la conférence I/O, Google a également annoncé le lancement de l’API Embeddings pour Vertex en avant-première, qui permet de convertir des données textuelles et des images en représentations appelées vecteurs, qui permettent d’établir des relations sémantiques spécifiques. Google explique que cette API sera utilisée pour construire des fonctionnalités de recherche sémantique et de classification de texte, comme les chatbots Q&A basés sur les données d’une organisation, l’analyse des sentiments et la détection d’anomalies.
Codey, Imagen, l’API Embeddings pour les images et RLHF sont disponibles dans Vertex AI pour les « testeurs de confiance », selon Google. Chirp, Embeddings API et Generative AI Studio, une suite permettant d’interagir avec des modèles d’IA et de les déployer, sont quant à eux accessibles en avant-première dans Vertex à toute personne disposant d’un compte Google Cloud.
