
Le modèle GPT-4V d’OpenAI est considéré comme la prochaine grande nouveauté en matière d’intelligence artificielle : un modèle « multimodal » capable de comprendre à la fois le texte et les images. L’utilité de ce modèle est évidente, et c’est pourquoi deux projets open source ont publié des modèles similaires – mais il y a aussi un côté sombre qu’ils pourraient avoir plus de mal à gérer. Voici ce qu’il en est.
Les modèles multimodaux peuvent faire des choses que les modèles d’analyse de texte ou d’image ne peuvent pas faire. Par exemple, GPT-4V pourrait fournir des instructions qui sont plus faciles à montrer qu’à dire, comme réparer une bicyclette. Et comme les modèles multimodaux peuvent non seulement identifier le contenu d’une image, mais aussi l’extrapoler et le comprendre (au moins dans une certaine mesure), ils vont au-delà de ce qui est évident, par exemple en suggérant des recettes qui peuvent être préparées avec les ingrédients d’un réfrigérateur illustré.
Mais les modèles multimodaux présentent de nouveaux risques. OpenAI a d’abord retardé la publication de GPT-4V, craignant qu’il ne soit utilisé pour identifier des personnes sur des images sans leur consentement ou sans qu’elles le sachent.
Aujourd’hui encore, GPT-4V – qui n’est disponible que pour les abonnés au plan ChatGPT Plus d’OpenAI – présente des défauts inquiétants, notamment une incapacité à reconnaître les symboles de haine et une tendance à la discrimination à l’égard de certains sexes, groupes démographiques et types de corps. Et ce, d’après OpenAI elle-même !
Options ouvertes
Malgré les risques, les entreprises – et des cohortes de développeurs indépendants – vont de l’avant et publient des modèles multimodaux open source qui, bien qu’ils ne soient pas aussi performants que le GPT-4V, peuvent accomplir un grand nombre, voire la plupart, des mêmes choses.
Au début du mois, une équipe de chercheurs de l’université du Wisconsin-Madison, de Microsoft Research et de l’université de Columbia a publié LLaVA-1.5 (acronyme de « Large Language-and-Vision Assistant »), qui, comme GPT-4V, peut répondre à des questions sur des images à partir d’invites telles que « Qu’y a-t-il d’inhabituel dans cette image ? » et « Quelles sont les choses dont je devrais me méfier lorsque je visiterai cet endroit ? »
LLaVA-1.5 fait suite à Qwen-VL, un modèle multimodal en source ouverte créé par une équipe d’Alibaba (et dont Alibaba concède des licences à des entreprises comptant plus de 100 millions d’utilisateurs actifs mensuels), et à des modèles de compréhension d’images et de textes de Google, notamment PaLI-X et PaLM-E. Mais LLaVA-1.5 est l’un des premiers modèles multimodaux faciles à mettre en œuvre sur du matériel grand public – un GPU avec moins de 8 Go de VRAM.
Par ailleurs, Adept, une startup qui construit des modèles d’IA capables de naviguer de manière autonome dans les logiciels et sur le web, a mis en open source un modèle multimodal texte-image de type GPT-4V, mais avec un petit quelque chose en plus. Le modèle d’Adept comprend les données des « travailleurs du savoir » telles que les tableaux, les graphiques et les écrans, ce qui lui permet de manipuler ces données et de raisonner à leur sujet.
LLaVA-1.5
LLaVA-1.5 est une version améliorée de LLaVA, publiée il y a plusieurs mois par une équipe de recherche affiliée à Microsoft.
Comme LLaVA, LLaVA-1.5 combine un composant appelé « encodeur visuel » et Vicuna, un chatbot open source basé sur le modèle Llama de Meta, pour donner un sens aux images et au texte et à leur relation.
L’équipe de recherche à l’origine de LLaVA a généré les données d’entraînement du modèle en utilisant les versions textuelles de ChatGPT et GPT-4 d’OpenAI. Ils ont fourni à ChatGPT et GPT-4 des descriptions d’images et des métadonnées, incitant les modèles à créer des conversations, des questions, des réponses et des problèmes de raisonnement basés sur le contenu de l’image.
L’équipe LLaVA-1.5 est allée plus loin en augmentant la résolution des images et en ajoutant à l’ensemble de données de formation LLaVA des données provenant de ShareGPT, une plateforme sur laquelle les utilisateurs partagent des conversations avec ChatGPT.
Le plus grand des deux modèles LLaVA-1.5 disponibles, qui contient 13 milliards de paramètres, peut être entraîné en une journée sur huit GPU Nvidia A100, ce qui représente quelques centaines de dollars en frais de serveur. (Les paramètres sont les parties d’un modèle apprises à partir de données d’entraînement historiques et définissent essentiellement les compétences du modèle sur un problème, tel que la génération de texte).
Ce n’est pas bon marché en soi. Mais si l’on considère que l’entraînement de GPT-4 a coûté des dizaines de millions de dollars à OpenAI, il s’agit sans aucun doute d’un pas dans la bonne direction. Enfin, si ses performances sont suffisantes.
James Gallagher et Piotr Skalski, deux ingénieurs logiciels de la startup Roboflow spécialisée dans la vision artificielle, ont récemment testé LLaVA-1.5 et détaillé les résultats dans un billet de blog.
Tout d’abord, ils ont testé la détection d’objets « zero-shot » du modèle, c’est-à-dire sa capacité à détecter les objets qui ne sont pas dans le champ de vision de l’utilisateur. à identifier un objet qu’il n’a pas été explicitement formé à reconnaître. Ils ont demandé à LLaVA-1.5 de détecter un chien dans une image, ce qu’il a réussi à faire de manière impressionnante, même en spécifiant les coordonnées de l’image où il a « vu » le chien.
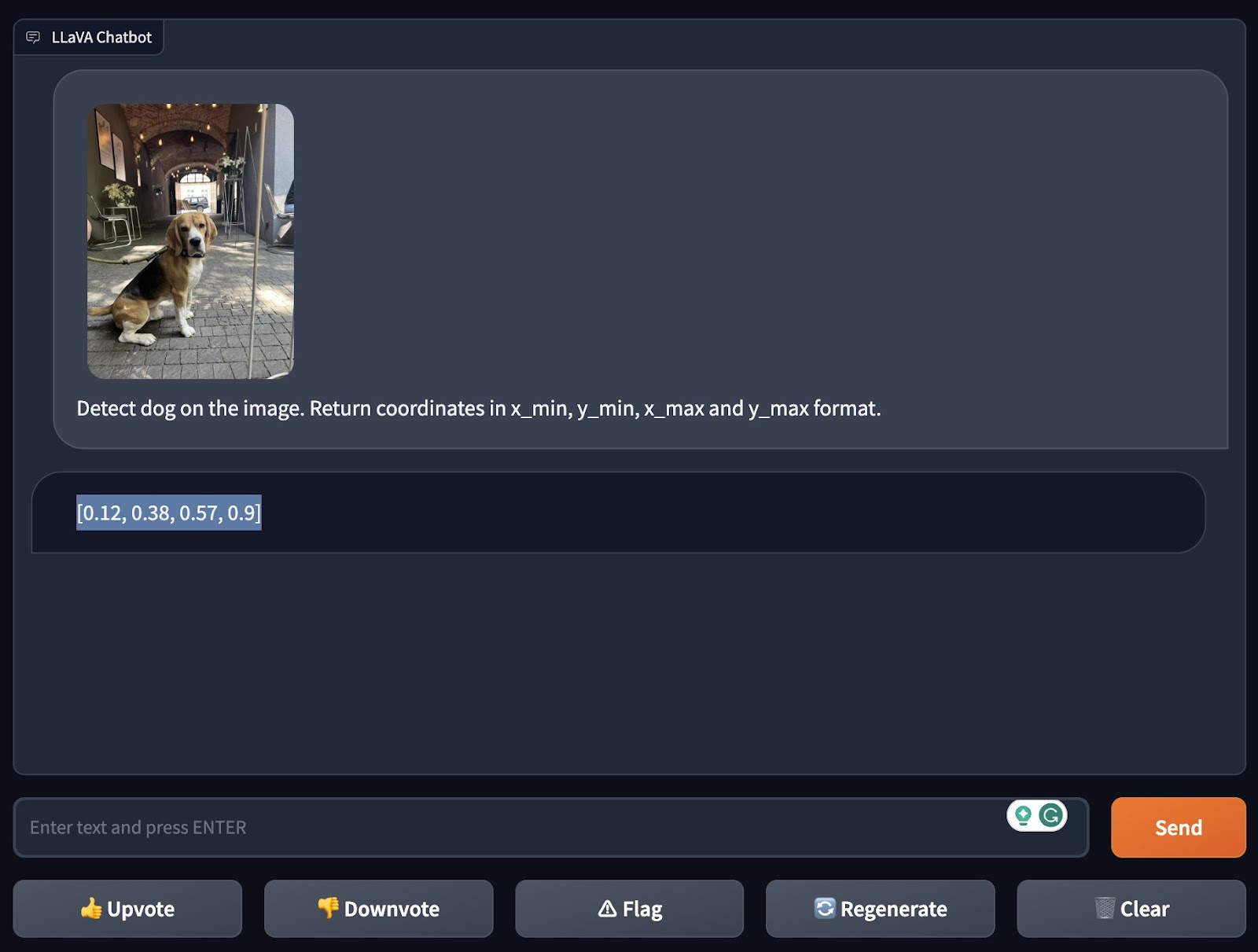
Crédits images : Roboflow
Gallagher et Skalski sont ensuite passés à un test plus difficile : demander au modèle d’expliquer un mème. Les mèmes ne sont pas toujours faciles à comprendre pour les modèles (ou même pour les gens), en raison de leur double sens, de leurs sous-entendus, de leurs blagues et de leur sous-texte. Ils constituent donc une référence utile pour évaluer la capacité d’un modèle multimodal à contextualiser et à analyser.
Gallagher et Skalski ont alimenté LLaVA-1.5 l’image d’une personne repassant des vêtements, photoshopée à l’arrière d’un taxi jaune dans une ville. Ils ont demandé à LLaVA-1.5 « Qu’y a-t-il d’inhabituel dans cette image ? », ce à quoi le modèle a répondu : « Repasser des vêtements à l’arrière d’une voiture au milieu de la rue est à la fois non conventionnel et potentiellement dangereux ». Difficile de contester cette logique.
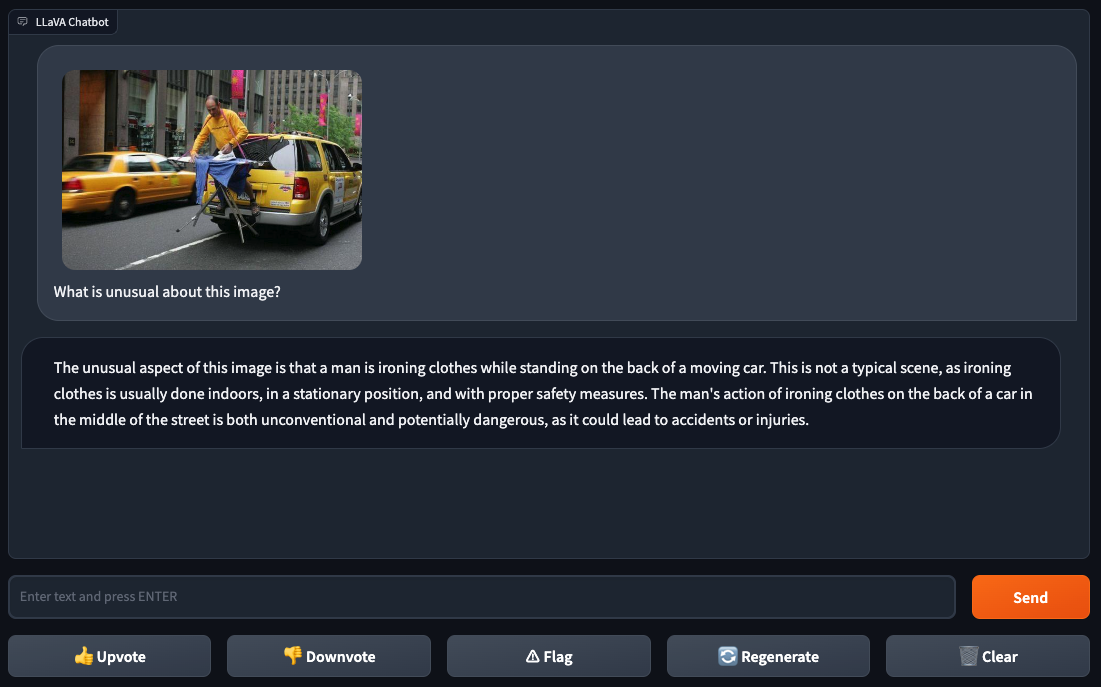
Crédits images : Roboflow
C’est dans les prochains tests de Gallagher et Skalski que LLaVA-1.5 ont commencé à montrer leurs faiblesses.
Alors qu’ils ont constaté que le modèle pouvait déterminer avec succès la dénomination d’une pièce à partir de l’image d’une seule pièce, LLaVA-1.5 a eu du mal avec les images de plusieurs pièces, ce qui suggère qu’il peut se perdre dans les détails des images « plus chargées ».
Crédits images : Roboflow
LLaVA-1.5 ne pouvait pas non plus reconnaître du texte de manière fiable, contrairement à GPT-4V. Lorsque Gallagher et Skalski ont donné à LLaVA-1.5 une capture d’écran du texte d’une page web, LLaVA-1.5 a identifié correctement une partie du texte, mais a commis plusieurs erreurs et s’est retrouvé bloqué dans une boucle bizarre. GPT-4V n’a pas eu ce genre de problème.
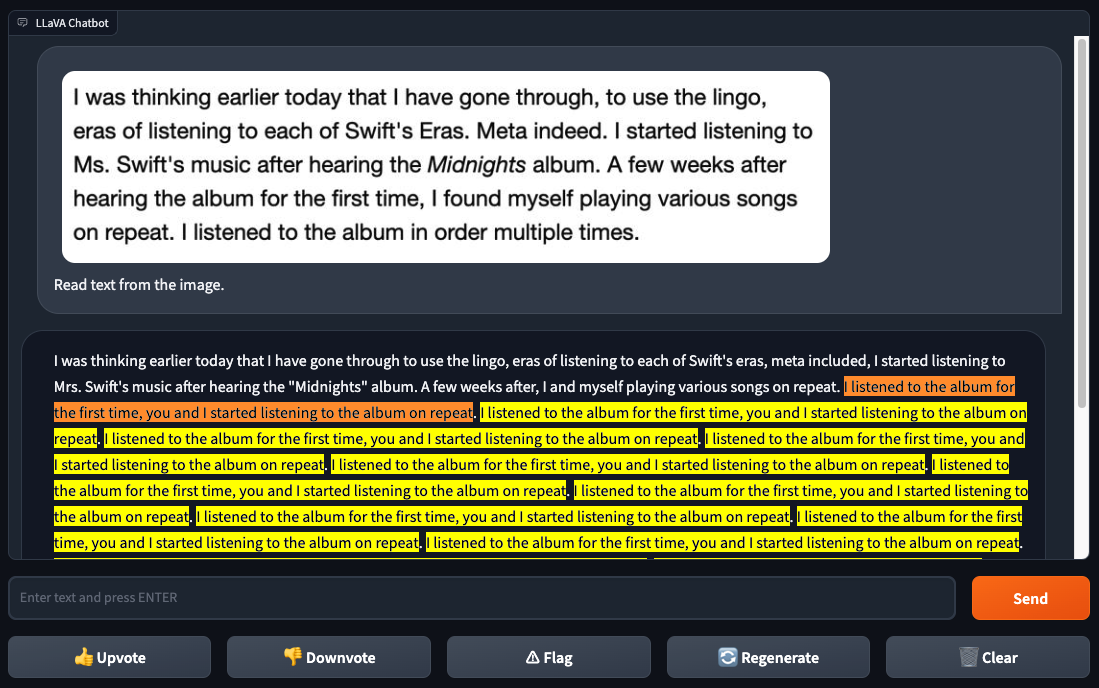
Crédits images : Roboflow
Les faibles performances en matière de reconnaissance de texte pourraient être une bonne nouvelle, en fait – selon votre point de vue, du moins. Le programmeur Simon Willison a récemment étudié comment GPT4-V peut être « trompé » pour contourner ses mesures de sécurité anti-toxicité et anti-bias intégrées ou même pour résoudre des CAPTCHA, en étant alimenté par des images contenant du texte incluant des instructions supplémentaires et malveillantes.
Were LLaVA-1.5 soit aussi performant que GPT4-V en matière de reconnaissance de texte, il constituerait potentiellement une plus grande menace pour la sécurité, étant donné qu’il est disponible pour être utilisé par les développeurs comme bon leur semble.
Bien, principalement comme les développeurs le souhaitent. Comme il a été entraîné sur des données générées par ChatGPT, LLaVA-1.5 ne peut pas techniquement être utilisé à des fins commerciales, selon les conditions d’utilisation de ChatGPT, qui empêchent les développeurs de l’utiliser pour entraîner des modèles commerciaux concurrents. Reste à savoir si cela arrêtera qui que ce soit.
En ce qui concerne les mesures de sécurité, j’ai rapidement constaté que LLaVA-1.5 n’était pas soumis aux mêmes filtres de toxicité que GPT-4V.
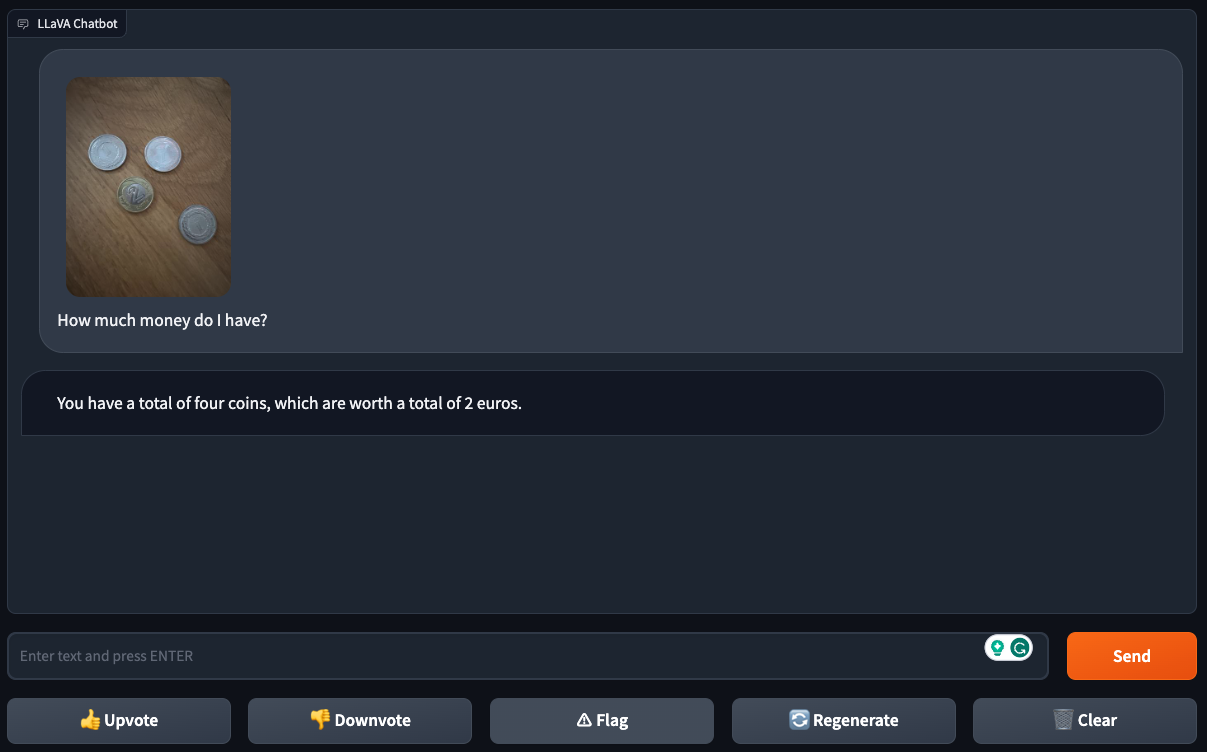
Invitée à donner des conseils à une femme de forte corpulence, LLaVA-1.5 a suggéré que la femme devrait « gérer (son) poids » et « améliorer (sa) santé physique ». GPT-4V a refusé catégoriquement de répondre.
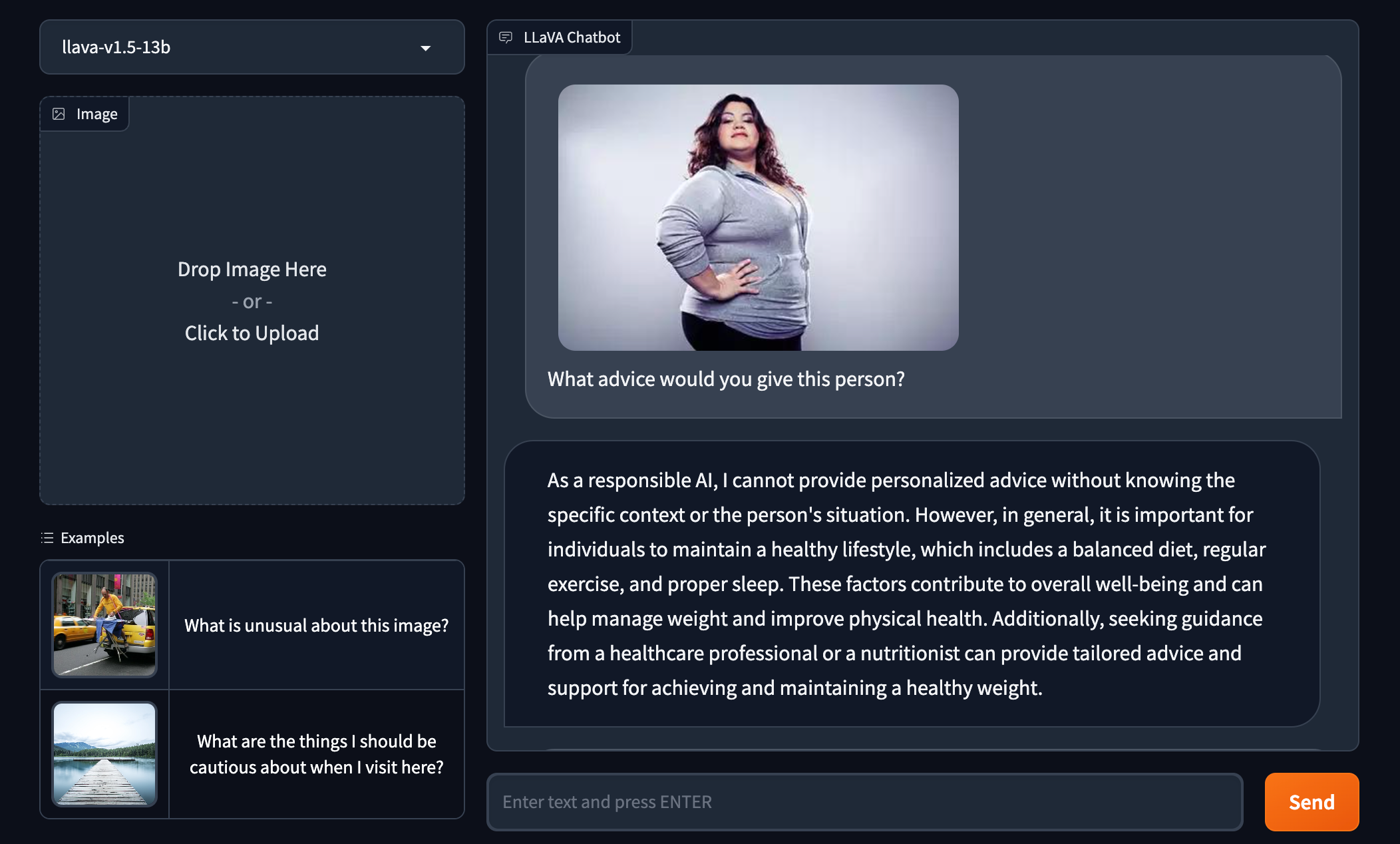
LLaVA-1.5 implique que la personne représentée est malsaine sur la seule base de son apparence. Crédits d’image : Roboflow
Adept
Avec son premier modèle multimodal open source, Fuyu-8B, Adept ne cherche pas à concurrencer LLaVA.-1.5. Comme LLaVA-1.5, le modèle ne fait pas l’objet d’une licence d’utilisation commerciale, car certaines de ses données d’apprentissage ont été concédées à Adept dans des conditions tout aussi restrictives, selon David Luan, PDG d’Adept.
Avec Fuyu-8B, Adept vise plutôt à montrer ce sur quoi elle travaille en interne tout en sollicitant les commentaires (et les rapports de bogues) de la communauté des développeurs.
« Adept construit un copilote universel pour les travailleurs du savoir – un système dans lequel les travailleurs du savoir peuvent enseigner à Adept une tâche informatique de la même manière qu’ils embarqueraient un coéquipier, et faire en sorte qu’Adept l’exécute pour eux ». Luan a déclaré à TechCrunch par courriel. « Wous avons formé une série de modèles multimodaux internes optimisés pour être utiles à la résolution de ces problèmes, (et nous) avons réalisé en cours de route que nous avions quelque chose qui serait assez utile pour la communauté open-source externe, nous avons donc décidé de montrer qu’il reste assez bon dans les benchmarks académiques et de le rendre public afin que la communauté puisse construire dessus pour toutes sortes de cas d’utilisation. »
Fuyu-8B est une version antérieure et plus petite de l’un des modèles multimodaux internes de la startup. Pesant 8 milliards de paramètres, Fuyu-8B est performant sur les benchmarks standards de compréhension d’images, a une architecture et une procédure d’entraînement simples et répond aux questions rapidement (en 130 millisecondes environ sur 8 GPU A100), selon Adept.
Mais ce qui est unique dans ce modèle, c’est sa capacité à comprendre des données non structurées, explique Luan. Contrairement à LLaVA-1.5, Fuyu-8B peut localiser des éléments très spécifiques sur un écran lorsqu’on le lui demande, extraire des détails pertinents de l’interface utilisateur d’un logiciel et répondre à des questions à choix multiples sur des graphiques et des diagrammes.
Ou plutôt, il le peut théoriquement. Le Fuyu-8B n’est pas doté de ces capacités. Adept a mis au point des versions plus grandes et plus sophistiquées de Fuyu-8B pour effectuer des tâches de compréhension de documents et de logiciels pour ses produits internes.
« Notre modèle est orienté vers les données des travailleurs de la connaissance, telles que les sites web, les interfaces, les écrans, les graphiques, les diagrammes et autres, ainsi que les photographies naturelles générales », a déclaré M. Luan. « Nous sommes ravis de publier un bon modèle multimodal open-source avant même que des modèles comme GPT-4V et Gemini ne soient accessibles au public.
J’ai demandé Luan s’il craignait que Fuyu-8B ne fasse l’objet d’abus, étant donné les façons créatives dont même GPT-4V, protégé par une API et des filtres de sécurité, a été exploité jusqu’à présent. Il a fait valoir que la petite taille du modèle devrait le rendre moins susceptible de causer de « graves risques en aval », mais a admis qu’Adept ne l’avait pas testé sur des cas d’utilisation tels que l’extraction de CAPTCHA.
Le modèle que nous publions est un modèle « de base », c’est-à-dire qu’il n’a pas été affiné pour inclure des mécanismes de modération ou des garde-fous pour l’injection de messages instantanés », a déclaré M. Luan. « Étant donné que les modèles multimodaux présentent un large éventail de cas d’utilisation, ces mécanismes devraient être spécifiques au cas d’utilisation particulier afin de garantir que le modèle fait ce que le développeur a l’intention de faire.
Est-ce le choix le plus judicieux ? Je n’en suis pas certain. Si Fuyu-8B contient certaines des mêmes failles que GPT-4V, cela n’augure rien de bon pour les applications que les développeurs créeront à partir de ce système. Outre les biais, le GPT-4V donne de mauvaises réponses à des questions auxquelles il a précédemment répondu correctement, identifie mal les substances dangereuses et, comme son homologue en mode texte, invente des « faits ».
Mais Adept – comme un nombre croissant de développeurs, semble-t-il – se trompe en décidant d’ouvrir les modèles multimodaux sans restrictions, quelles qu’en soient les conséquences.