Suivre l’évolution d’un secteur aussi rapide que l’IA n’est pas une mince affaire. En attendant qu’une IA puisse le faire à votre place, voici un récapitulatif pratique des événements récents dans le monde de l’apprentissage automatique, ainsi que des recherches et expériences notables que nous n’avons pas couvertes par elles-mêmes.
Cette semaine, il était impossible d’ignorer – y compris pour ce journaliste, à la grande consternation de mon cerveau en manque de sommeil – la controverse sur la direction de la startup d’IA OpenAI. Le conseil d’administration a évincé Sam Altman, PDG et cofondateur, en raison de ce qu’il considérait comme des priorités mal placées de sa part : la commercialisation de l’IA au détriment de la sécurité.
M. Altman a été rétabli dans ses fonctions de PDG et la plupart des membres du conseil d’administration initial ont été remplacés, en grande partie grâce aux efforts de Microsoft, l’un des principaux bailleurs de fonds d’OpenAI. Mais cette saga illustre les dangers auxquels s’exposent les entreprises d’IA, même celles qui sont aussi importantes et influentes qu’OpenAI, car la tentation d’exploiter… monétisation-Les sources de financement orientées vers la monétisation sont de plus en plus nombreuses.
Ce n’est pas que les laboratoires d’IA veulent de s’associer à des sociétés de capital-risque et à des géants de la technologie alignés sur le plan commercial et avides de rendement. C’est que les coûts élevés de formation et de développement des modèles d’IA rendent presque impossible d’éviter ce destin.
Selon CNBC, le processus de formation d’un grand modèle linguistique tel que GPT-3, le prédécesseur du modèle d’IA générateur de texte phare d’OpenAI, GPT-4, pourrait coûter plus de 4 millions de dollars. Cette estimation ne tient pas compte du coût de l’embauche de scientifiques des données, d’experts en IA et d’ingénieurs en logiciel, qui perçoivent tous des salaires élevés.
Ce n’est pas un hasard si de nombreux grands laboratoires d’IA ont conclu des accords stratégiques avec des fournisseurs de clouds publics ; l’informatique, en particulier à une époque où les puces nécessaires à l’entraînement des modèles d’IA sont rares (ce qui profite à des fournisseurs comme Nvidia), est devenue plus précieuse que l’or pour ces laboratoires. Anthropic, le principal rival d’OpenAI, a bénéficié d’investissements de Google et d’Amazon. Cohere et Character.ai, quant à eux, bénéficient du soutien de Google Cloud, qui est également leur fournisseur exclusif d’infrastructure de calcul.
Mais, comme l’a montré cette semaine, ces investissements comportent des risques. Les géants de la technologie ont leurs propres objectifs – et le poids nécessaire pour faire aboutir leurs projets.
OpenAI a tenté de conserver une certaine indépendance grâce à une structure unique de « plafonnement des bénéfices » qui limite les rendements totaux des investisseurs. Une grande partie de l’investissement de Microsoft dans OpenAI se fait sous la forme de crédits Azure, et la menace de retenir ces crédits suffirait à attirer l’attention de n’importe quel conseil d’administration.
À moins d’une augmentation massive des investissements dans les ressources publiques de supercalculateurs ou dans les programmes de subventions à l’IA, le statu quo ne semble pas près de changer. Les startups d’IA d’une certaine taille – comme la plupart des startups – sont obligées de céder le contrôle de leur destin si elles souhaitent se développer. Espérons que, contrairement à OpenAI, elles concluent un accord avec le diable qu’elles connaissent.
Voici d’autres articles sur l’IA parus ces derniers jours :
- L’OpenAI ne va pas détruire l’humanité : OpenAI a-t-elle inventé une technologie d’IA susceptible de « menacer l’humanité » ? À en croire certains titres récents, on pourrait être enclin à le penser. Pourtant, selon les experts, il n’y a pas lieu de s’alarmer.
- La Californie se penche sur les règles de l’IA : L’agence californienne de protection de la vie privée se prépare à son prochain tour de passe-passe : La mise en place de garde-fous pour l’IA. Natasha écrit que l’agence californienne de protection de la vie privée a récemment publié un projet de réglementation sur la manière dont les données personnelles peuvent être utilisées pour l’IA, en s’inspirant des règles en vigueur dans l’Union européenne.
- Bard répond aux questions de YouTube : Google a annoncé que son chatbot Bard AI peut désormais répondre à des questions sur les vidéos YouTube. Bien que Bard ait déjà eu la possibilité d’analyser des vidéos YouTube avec le lancement de l’extension YouTube en septembre dernier, le chatbot peut maintenant vous donner des réponses spécifiques sur des questions liées au contenu d’une vidéo.
- Lancement de Grok de X : Peu après l’apparition de captures d’écran montrant Grok, le chatbot de xAI, sur l’application web de X, Elon Musk, propriétaire de X, a confirmé que Grok serait disponible pour tous les abonnés Premium+ de la société dans le courant de la semaine. Bien que les déclarations de Musk sur les délais de livraison des produits n’aient pas toujours été confirmées, l’évolution du code de l’application X révèle que l’intégration de Grok est en bonne voie.
- Stability AI lance un générateur de vidéos : La startup Stability AI a annoncé la semaine dernière Stable Video Diffusion, un modèle d’IA qui génère des vidéos en animant des images existantes. Basé sur le modèle texte-image Stable Diffusion de Stability, Stable Video Diffusion est l’un des rares modèles de génération de vidéos disponibles en open source – ou dans le commerce, d’ailleurs.
- Communiqués anthropiques Claude 2.1 : Anthropic a récemment publié Claude 2.1, une amélioration de son modèle phare de grand langage qui lui permet de rester compétitif par rapport à la série GPT d’OpenAI. Devin écrit que la nouvelle mise à jour de Claude comporte trois améliorations majeures : la fenêtre contextuelle, la précision et l’extensibilité.
- OpenAI et IA ouverte : Paul écrit que la débâcle d’OpenAI a mis en lumière les forces qui contrôlent la révolution naissante de l’IA, amenant de nombreuses personnes à s’interroger sur ce qui se passe si l’on mise tout sur un acteur propriétaire centralisé – et sur ce qui se passe si les choses tournent mal par la suite.
- AI21 Labs lève des fonds : AI21 Labs, une société qui développe des produits d’IA générative dans la lignée de GPT-4 et ChatGPT d’OpenAI, a levé la semaine dernière 53 millions de dollars – ce qui porte son total levé à 336 millions de dollars. Startup basée à Tel Aviv créant une gamme d’outils d’IA génératrice de texte, AI21 Labs a été fondée en 2017 par Amnon Shashua, cofondateur de Mobileye, Ori Goshen et Yoav Shoham, l’autre codirecteur général de la startup.
Plus d’informations sur l’apprentissage automatique
Rendre les modèles d’IA plus francs lorsqu’ils ont besoin de plus d’informations pour produire une réponse fiable est un problème difficile, car en réalité, le modèle ne sait pas faire la différence entre le vrai et le faux. Mais en obligeant le modèle à dévoiler un peu son fonctionnement interne, on peut avoir une meilleure idée des cas où il est le plus susceptible de mentir.

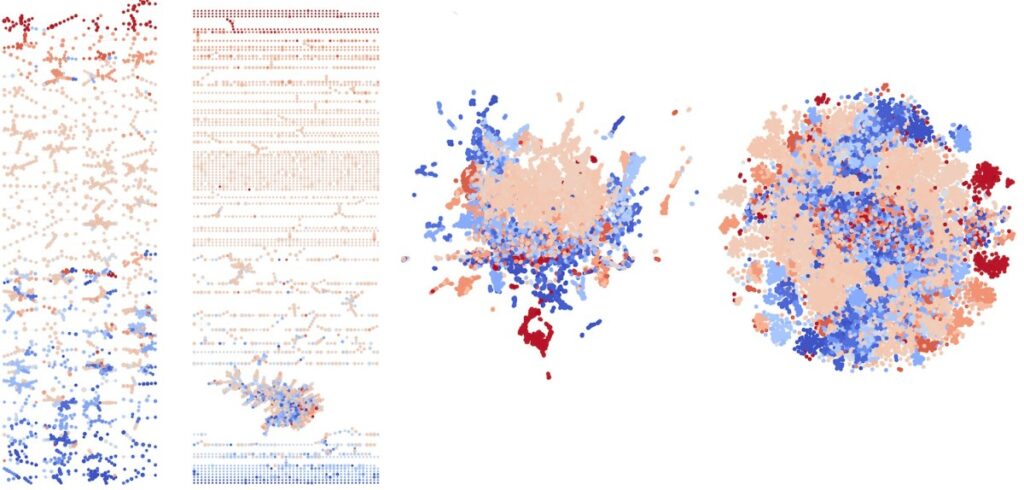
Crédits d’image : Université de Purdue
Ce travail de Purdue crée une « carte de Reeb » lisible par l’homme sur la manière dont le réseau neuronal représente les concepts visuels dans son espace vectoriel. Les éléments qu’il juge similaires sont regroupés, et les chevauchements avec d’autres zones peuvent indiquer soit des similitudes entre ces groupes, soit une confusion de la part du modèle. « Ce que nous faisons, c’est prendre ces ensembles compliqués d’informations provenant du réseau et donner aux gens un aperçu de la façon dont le réseau perçoit les données à un niveau macroscopique », a déclaré le chercheur principal David Gleich.

Crédits d’image : Laboratoire national de Los Alamos
Si votre ensemble de données est limité, il est préférable de ne pas trop extrapoler, mais si vous devez le faire… un outil comme « Senseiver », du laboratoire national de Los Alamos, est peut-être la meilleure solution. Le modèle est basé sur le Perceiver de Google et est capable de prendre une poignée de mesures éparses et – apparemment – de faire des prédictions étonnamment précises en comblant les lacunes.
Il pourrait s’agir de mesures climatiques, d’autres relevés scientifiques ou même de données 3D telles que des cartes à faible fidélité créées par des scanners à haute altitude. Le modèle peut fonctionner sur des ordinateurs périphériques, comme les drones, qui peuvent désormais effectuer des recherches de caractéristiques spécifiques (dans leur cas d’essai, des fuites de méthane) au lieu de simplement lire les données puis de les ramener pour les analyser plus tard.
Pendant ce temps, les chercheurs s’efforcent de rendre le matériel qui fait fonctionner ces réseaux neuronaux plus proche d’un réseau neuronal lui-même. Ils ont fabriqué un réseau de 16 électrodes qu’ils ont ensuite recouvert d’un lit de fibres conductrices formant un réseau aléatoire mais constamment dense. Là où elles se chevauchent, ces fibres peuvent soit former des connexions, soit les rompre, en fonction d’un certain nombre de facteurs. D’une certaine manière, cela ressemble beaucoup à la façon dont les neurones de notre cerveau forment des connexions, puis les renforcent ou les abandonnent de manière dynamique.
L’équipe de l’UCLA et de l’Université de Sydney a déclaré que le réseau était capable d’identifier des chiffres écrits à la main avec une précision de 93,4 %, ce qui est en fait supérieur à une approche plus conventionnelle à une échelle similaire. C’est fascinant, certes, mais on est encore loin d’une utilisation pratique, même si les réseaux auto-organisés finiront probablement par trouver leur place dans la boîte à outils.

Crédits d’image : UCLA/Université de Sydney
Il est agréable de voir des modèles d’apprentissage automatique aider les gens, et nous en avons quelques exemples cette semaine.
Un groupe de chercheurs de Stanford travaille sur un outil appelé GeoMatch destiné à aider les réfugiés et les immigrés à trouver l’endroit qui correspond à leur situation et à leurs compétences. Il ne s’agit pas d’une procédure automatisée : à l’heure actuelle, ces décisions sont prises par des agents de placement et d’autres fonctionnaires qui, bien qu’expérimentés et informés, ne peuvent pas toujours être sûrs que leurs choix sont étayés par des données. Le modèle GeoMatch prend en compte un certain nombre de caractéristiques et suggère un lieu où la personne est susceptible de trouver un emploi solide.
« Ce qui demandait autrefois des heures de recherche à plusieurs personnes peut désormais être réalisé en quelques minutes », a déclaré le chef du projet, Michael Hotard. « GeoMatch peut être un outil incroyablement utile pour simplifier le processus de collecte d’informations et d’établissement de liens ».
À l’université de Washington, des chercheurs en robotique viennent de présenter leurs travaux sur la création d’un système d’alimentation automatisé pour les personnes qui ne peuvent pas manger seules. Le système a connu de nombreuses versions et a évolué en fonction des réactions de la communauté, et « nous en sommes arrivés au point où nous pouvons ramasser presque tout ce qu’une fourchette peut manipuler. Nous ne pouvons donc pas prendre de soupe, par exemple. Mais le robot peut tout prendre, de la purée de pommes de terre ou de nouilles à la salade de fruits ou de légumes, en passant par la pizza prédécoupée, le sandwich ou les morceaux de viande », a déclaré Ethan K. Gordon, codirecteur du projet, dans une séance de questions-réponses publiée par l’université.

Crédits d’image : Université de Washington
Il s’agit d’une discussion intéressante, qui montre que des projets de ce type ne sont jamais vraiment « terminés », mais qu’à chaque étape, ils peuvent aider de plus en plus de personnes.
Il existe quelques projets destinés à aider les aveugles à se déplacer dans le monde, de Be My AI (alimenté par GPT-4V) à Seeing AI de Microsoft, une collection de modèles spécialement conçus pour les tâches quotidiennes. Google avait la sienne, une application de recherche de chemin appelée Project Guideline, destinée à aider les personnes à rester sur la bonne voie lorsqu’elles marchent ou font leur jogging sur un chemin. Google vient de la rendre open source, ce qui signifie généralement qu’il abandonne quelque chose – mais sa perte profite à d’autres chercheurs, car le travail effectué par l’entreprise milliardaire peut désormais être utilisé dans le cadre d’un projet personnel.
Enfin, un peu d’amusement avec FathomVerse, un jeu/outil qui permet d’identifier les créatures marines à la manière des applications comme iNaturalist et autres qui identifient les feuilles et les plantes. Il a besoin de votre aide, car les animaux comme les anémones et les pieuvres sont mous et difficiles à identifier. Alors, inscrivez-vous à la version bêta et voyez si vous pouvez aider à faire décoller cette application !

Crédits images : FathomVerse