
Lors de sa conférence re:Invent aujourd’hui, la branche AWS cloud d’Amazon a annoncé le lancement de SageMaker HyperPod, un nouveau service spécialement conçu pour la formation et l’optimisation de grands modèles de langage (LLM). SageMaker HyperPod est maintenant disponible.
Amazon mise depuis longtemps sur SageMaker, son service de construction, d’entraînement et de déploiement de modèles d’apprentissage automatique, comme épine dorsale de sa stratégie d’apprentissage automatique. Aujourd’hui, avec l’avènement de l’IA générative, il n’est peut-être pas surprenant qu’elle s’appuie également sur SageMaker en tant que produit de base pour permettre à ses utilisateurs d’entraîner et d’affiner plus facilement les LLM.

Crédits d’image : AWS
« SageMaker HyperPod vous permet de créer un cluster distribué avec des instances accélérées, optimisées pour la formation distribuée », m’a déclaré Ankur Mehrotra, directeur général d’AWS pour SageMaker, lors d’un entretien en amont de l’annonce d’aujourd’hui. « Il vous donne les outils pour distribuer efficacement les modèles et les données à travers votre cluster, ce qui accélère votre processus de formation.
Il a également noté que SageMaker HyperPod permet aux utilisateurs de sauvegarder fréquemment des points de contrôle, ce qui leur permet d’interrompre, d’analyser et d’optimiser le processus d’apprentissage sans avoir à le recommencer. Le service comprend également un certain nombre de protections contre les défaillances, de sorte que si un GPU tombe en panne pour une raison ou une autre, l’ensemble du processus d’apprentissage ne tombe pas en panne non plus.
« Pour une équipe de ML, par exemple, qui ne s’intéresse qu’à l’entraînement du modèle, cela devient une expérience sans contact et le cluster devient en quelque sorte un cluster auto-réparateur », a expliqué M. Mehrotra. « Globalement, ces capacités peuvent vous aider à former des modèles de base jusqu’à 40 % plus rapidement, ce qui, si vous pensez au coût et au délai de mise sur le marché, est un facteur de différenciation énorme.
Crédits d’image : AWS
Les utilisateurs peuvent choisir de s’entraîner sur les puces Trainium (et maintenant Trainium 2) personnalisées d’Amazon ou sur des instances GPU basées sur Nvidia, y compris celles qui utilisent le processeur H100. L’entreprise promet qu’HyperPod peut accélérer le processus de formation jusqu’à 40 %.
La société a déjà acquis une certaine expérience dans ce domaine en utilisant SageMaker pour construire des LLM. Le modèle Falcon 180B, par exemple, a été entraîné sur SageMaker, en utilisant un cluster de milliers de GPU A100. M. Mehrotra note qu’AWS a pu utiliser ce qu’elle a appris de cette expérience et de son expérience antérieure de la mise à l’échelle de SageMaker pour construire HyperPod.
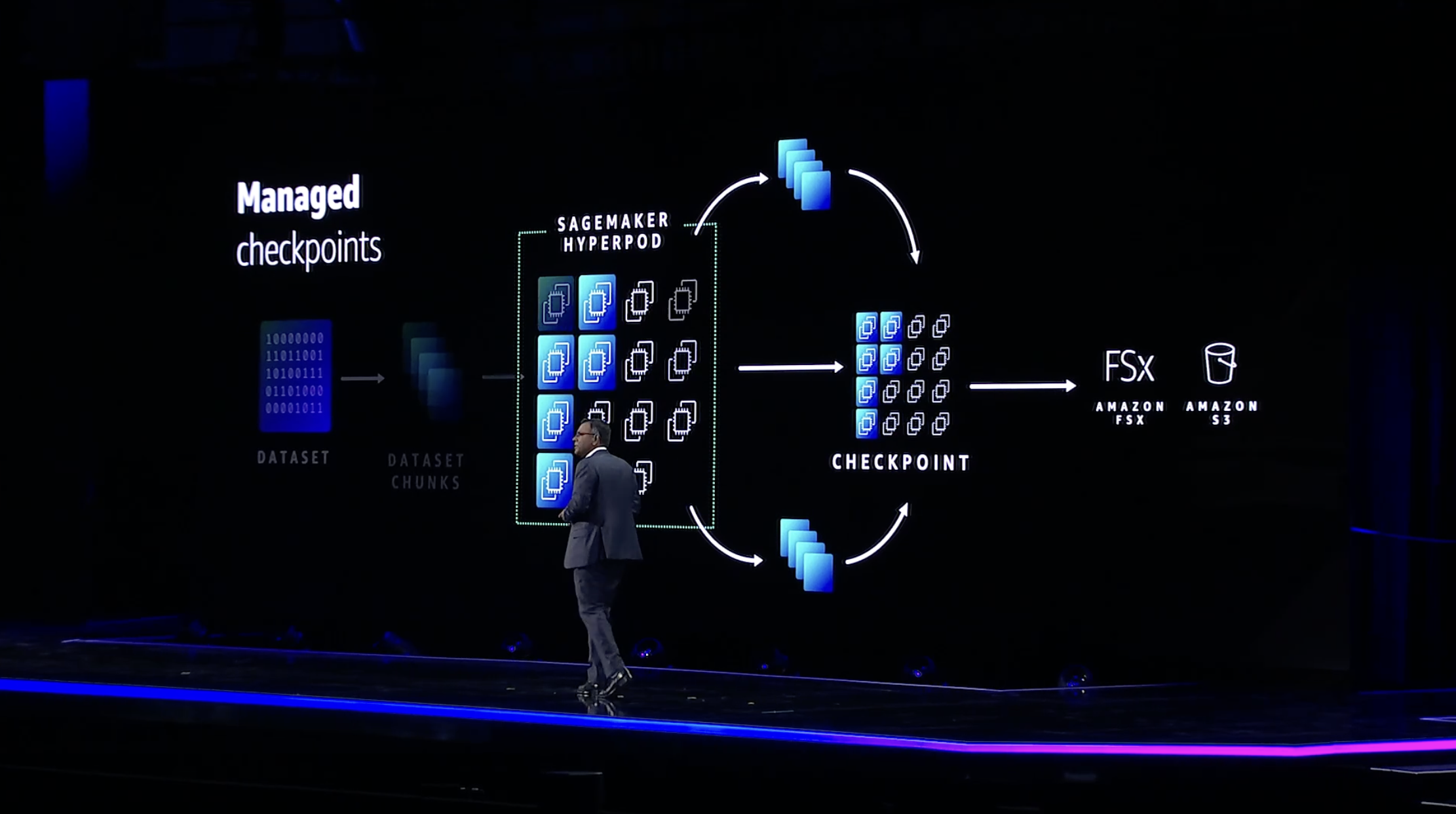
Crédits d’image : AWS
Aravind Srinivas, cofondateur et PDG de Perplexity AI, m’a expliqué que son entreprise avait bénéficié d’un accès anticipé au service lors de sa version bêta privée. Il a indiqué que son équipe était initialement sceptique quant à l’utilisation d’AWS pour l’entraînement et l’affinement de ses modèles.
« Nous ne travaillions pas avec AWS auparavant », a-t-il déclaré. « Il y avait un mythe – c’est un mythe, ce n’est pas un fait – selon lequel AWS ne dispose pas d’une grande infrastructure pour l’entraînement de grands modèles et, évidemment, nous n’avions pas le temps de faire preuve de diligence raisonnable, alors nous avons cru à ce mythe. » L’équipe a toutefois été mise en contact avec AWS et les ingénieurs leur ont demandé de tester le service (gratuitement). Il a également noté qu’il a trouvé facile d’obtenir le soutien d’AWS – et l’accès à suffisamment de GPU pour le cas d’utilisation de Perplexity. Le fait que l’équipe soit déjà familiarisée avec l’inférence sur AWS a évidemment aidé.
Srinivas a également souligné que l’équipe HyperPod d’AWS s’est fortement concentrée sur l’accélération des interconnexions qui relient les cartes graphiques de Nvidia. « Ils ont optimisé les primitives – les diverses primitives de Nvidia – qui vous permettent de communiquer ces gradients et ces paramètres entre différents nœuds », a-t-il expliqué.
