
Alors que les investisseurs s’apprêtaient à sortir de leur réserve après l’éviction sans ménagement de Sam Altman d’OpenAI et que ce dernier préparait son retour dans l’entreprise, les membres de l’équipe Superalignment d’OpenAI travaillaient assidûment sur le problème de la maîtrise d’une IA plus intelligente que l’homme.
C’est du moins l’impression qu’ils veulent donner.
Cette semaine, j’ai pris contact avec trois membres de l’équipe Superalignment – Collin Burns, Pavel Izmailov et Leopold Aschenbrenner – qui se trouvaient à la Nouvelle-Orléans. à NeurIPS, la conférence annuelle sur l’apprentissage automatique, pour présenter Les derniers travaux de l’OpenAI visant à garantir que les systèmes d’IA se comportent comme prévu.
L’OpenAI a formé l’équipe Superalignment en juillet pour développer des moyens de diriger, réguler et gouverner les systèmes d’IA « superintelligents », c’est-à-dire des systèmes théoriques dont l’intelligence dépasse de loin celle de l’homme.
« Aujourd’hui, nous pouvons essentiellement aligner des modèles qui sont plus stupides que nous, ou peut-être de l’ordre de l’intelligence humaine. au maximum« , a déclaré M. Burns. « L’alignement d’un modèle qui est en fait plus intelligent que nous est beaucoup, beaucoup moins évident – comment pouvons-nous même le faire ? »
L’effort de Superalignment est dirigé par le cofondateur et scientifique en chef d’OpenAI, Ilya Sutskever, ce qui n’a pas fait sourciller en juillet – mais certainement maintenant, à la lumière du fait que Sutskever était parmi ceux qui ont initialement poussé au licenciement d’Altman. Alors que certains rapports suggèrent que Sutskever est dans un « état de limbes » après le retour d’Altman, les relations publiques d’OpenAI me disent que Sutskever est en effet – au moins à partir d’aujourd’hui – toujours à la tête de l’équipe de Superalignment.
Le superalignement est un sujet délicat au sein de la communauté des chercheurs en IA. Certains affirment que le sous-domaine est prématuré ; d’autres laissent entendre qu’il s’agit d’une fausse piste.
Alors qu’Altman a suscité des comparaisons entre OpenAI et le projet Manhattan, allant jusqu’à réunir une équipe chargée d’étudier les modèles d’IA pour se protéger contre les « risques catastrophiques », y compris les menaces chimiques et nucléaires, certains experts affirment qu’il n’y a pas beaucoup d’éléments qui suggèrent que la technologie de la startup atteindra bientôt – ou jamais – des capacités qui mettront fin au monde et dépasseront l’intelligence de l’homme. Les affirmations de superintelligence imminente, ajoutent ces experts, ne servent qu’à attirer délibérément l’attention sur les questions urgentes de réglementation de l’IA, telles que les biais algorithmiques et la tendance à la toxicité de l’IA, et à détourner l’attention de ces questions.
Pour ce que cela vaut, Suksever semble croire sincèrement que l’IA – pas celle d’OpenAI en tant que telle, mais la une certaine incarnation pourrait un jour constituer une menace existentielle. Il serait allé jusqu’à commander et brûler une effigie en bois dans une entreprise hors site pour démontrer son engagement à empêcher l’IA de nuire à l’humanité, et commander une quantité significative de calcul d’OpenAI – 20 % de ses puces informatiques existantes – pour les recherches de l’équipe de Superalignment.
« Les progrès de l’IA ont été extraordinairement rapides ces derniers temps, et je peux vous assurer qu’ils ne ralentissent pas », a déclaré M. Aschenbrenner. « Je pense que nous atteindrons bientôt des systèmes de niveau humain, mais cela ne s’arrêtera pas là – nous irons jusqu’à des systèmes surhumains… Alors, comment aligner les systèmes d’IA surhumains et les rendre sûrs ? C’est vraiment un problème pour toute l’humanité – peut-être le problème technique non résolu le plus important de notre époque ».
L’équipe Superalignment tente actuellement d’élaborer des cadres de gouvernance et de contrôle qui pourraient s’appliquer à de futurs systèmes d’IA puissants. La tâche n’est pas simple, car la définition de la « superintelligence » – et la question de savoir si un système d’IA particulier l’a atteinte – fait l’objet d’un débat animé. Mais l’approche retenue par l’équipe pour l’instant consiste à utiliser un modèle d’IA plus faible et moins sophistiqué (par exemple GPT-2) pour guider un modèle plus avancé et plus sophistiqué (GPT-4) dans des directions souhaitables – et à l’écart des directions non souhaitables.
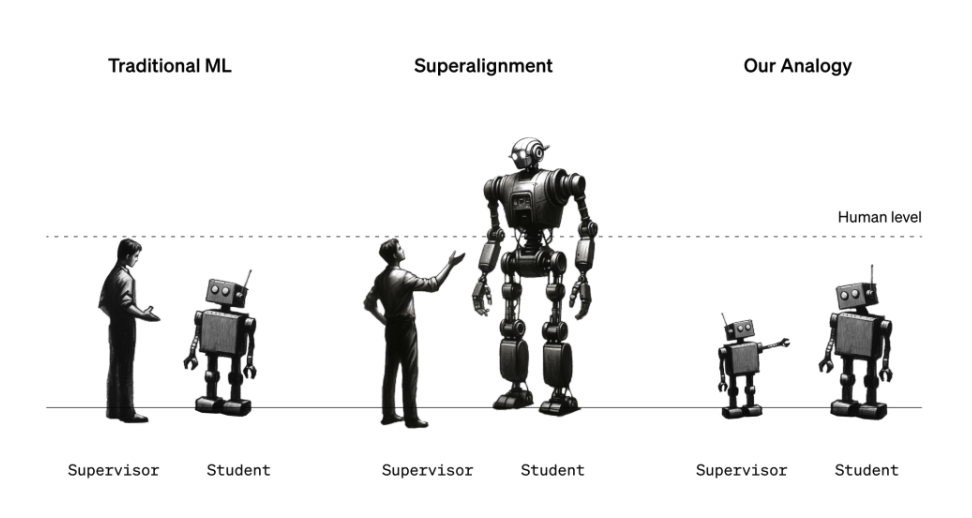
Figure illustrant l’analogie de l’équipe Superalignment basée sur l’IA pour aligner les systèmes superintelligents.
« Une grande partie de ce que nous essayons de faire consiste à dire à un modèle ce qu’il doit faire et à s’assurer qu’il le fera », a déclaré M. Burns. « Comment faire en sorte qu’un modèle suive des instructions et qu’il n’aide qu’avec des choses qui sont vraies et non pas qu’il invente des choses ? Comment faire en sorte qu’un modèle nous dise si le code qu’il a généré est sûr ou s’il s’agit d’un comportement grave ? Tels sont les types de tâches que nous voulons être en mesure de réaliser grâce à notre recherche ».
Mais attendez, direz-vous, quel est le rapport entre l’IA guidant l’IA et la prévention de l’IA menaçant l’humanité ? Il s’agit d’une analogie : le modèle faible est censé représenter les superviseurs humains, tandis que le modèle fort représente l’IA superintelligente. À l’instar des humains qui pourraient ne pas être en mesure de comprendre un système d’IA superintelligent, le modèle faible ne peut pas « comprendre » toutes les complexités et les nuances du modèle fort, ce qui rend la configuration utile pour vérifier les hypothèses de superalignement, selon l’équipe de Superalignment.
« On peut imaginer un élève de sixième année essayant de superviser un étudiant d’université », explique Izmailov. « Disons que l’élève de sixième année essaie d’expliquer à l’étudiant une tâche qu’il sait en quelque sorte comment résoudre… Même si la supervision de l’élève de sixième année peut comporter des erreurs dans les détails, on peut espérer que l’étudiant comprendra l’essentiel et sera capable d’accomplir la tâche mieux que le superviseur. »
Dans la configuration de l’équipe Superalignment, un modèle faible affiné sur une tâche particulière génère des étiquettes qui sont utilisées pour « communiquer » les grandes lignes de cette tâche au modèle fort. Compte tenu de ces étiquettes, le modèle fort peut généraliser plus ou moins correctement selon l’intention du modèle faible – même si les étiquettes du modèle faible contiennent des erreurs et des biais, a constaté l’équipe.
L’approche modèle faible-modèle fort pourrait même conduire à des percées dans le domaine des hallucinations, affirme l’équipe.
« Les hallucinations sont en fait très intéressantes, parce qu’en interne, le modèle sait si ce qu’il dit est vrai ou faux », a déclaré Aschenbrenner. « Mais de la manière dont ces modèles sont formés aujourd’hui, les superviseurs humains les récompensent par des « pouces en l’air » ou des « pouces en bas » lorsqu’ils disent des choses. Ainsi, parfois, par inadvertance, les humains récompensent le modèle pour avoir dit des choses qui sont soit fausses, soit que le modèle ne connaît pas, etc. Si nous réussissons dans nos recherches, nous devrions développer des techniques qui nous permettraient de convoquer les connaissances du modèle et d’appliquer cette convocation à la question de savoir si quelque chose est vrai ou faux et de l’utiliser pour réduire les hallucinations ».
Mais l’analogie n’est pas parfaite. L’OpenAI veut donc faire appel à la foule pour trouver des idées.
À cette fin, OpenAI lance un programme de subventions de 10 millions de dollars pour soutenir la recherche technique sur l’alignement superintelligent, dont des tranches seront réservées aux laboratoires universitaires, aux organisations à but non lucratif, aux chercheurs individuels et aux étudiants de troisième cycle. OpenAI prévoit également d’organiser une conférence universitaire sur le superalignement au début de l’année 2025, au cours de laquelle elle partagera et promouvra les travaux des finalistes du prix du superalignement.
Curieusement, une partie du financement de la bourse proviendra de l’ancien PDG et président de Google, Eric Schmidt. M. Schmidt – ardent défenseur de M. Altman – est en passe de devenir un enfant-vedette du doomérisme en matière d’IA, affirmant que l’arrivée de systèmes d’IA dangereux est imminente et que les régulateurs n’en font pas assez pour s’y préparer. Ce n’est pas nécessairement par altruisme – les rapports de Protocol et de Wired notent que M. Schmidt, un investisseur actif dans le domaine de l’IA, pourrait bénéficier d’énormes avantages commerciaux si le gouvernement américain mettait en œuvre le plan qu’il a proposé pour soutenir la recherche sur l’IA.
Le don pourrait être perçu comme un signal de vertu d’un point de vue cynique. La fortune personnelle de M. Schmidt est estimée à 24 milliards de dollars et il a injecté des centaines de millions dans d’autres entreprises et fonds d’IA nettement moins axés sur l’éthique, y compris le sien.
Schmidt nie bien sûr que ce soit le cas.
« L’IA et d’autres technologies émergentes sont en train de remodeler notre économie et notre société », a-t-il déclaré dans un communiqué envoyé par courriel. « Il est essentiel de veiller à ce qu’elles soient conformes aux valeurs humaines, et je suis fier de soutenir les nouvelles subventions de l’OpenAI visant à développer et à contrôler l’IA de manière responsable, dans l’intérêt du public.
En effet, l’implication d’une personnalité aux motivations commerciales aussi transparentes soulève la question suivante : les recherches de l’OpenAI sur le superalignement, ainsi que celles qu’elle encourage la communauté à soumettre à sa future conférence, seront-elles mises à la disposition de tous pour qu’ils les utilisent comme bon leur semble ?
L’équipe de Superalignment m’a assuré que, oui, les recherches d’OpenAI – y compris le code – et le travail d’autres personnes qui reçoivent des subventions et des prix d’OpenAI pour des travaux liés au superalignement seront partagés publiquement. Nous demanderons à l’entreprise de s’y tenir.
« Contribuer non seulement à la sécurité de nos modèles, mais aussi à celle des modèles d’autres laboratoires et de l’IA avancée en général fait partie de notre mission », a déclaré M. Aschenbrenner. « Il s’agit d’un élément essentiel de notre mission, qui consiste à développer l’IA au profit de l’ensemble de l’humanité, en toute sécurité. Et nous pensons qu’il est absolument essentiel de mener ces recherches pour que l’IA soit bénéfique et sûre. »