
Avec la pandémie comme accélérateur, le secteur des soins de santé adopte l’IA avec enthousiasme. Selon une étude réalisée en 2020 par Optum, 80 % des organismes de santé ont mis en place une stratégie d’IA, tandis que 15 % prévoient d’en lancer une.
Les fournisseurs – y compris les grandes entreprises technologiques – se développent pour répondre à la demande. Google a récemment dévoilé Med-PaLM 2, un modèle d’IA conçu pour répondre aux questions médicales et trouver des informations dans les textes médicaux. Par ailleurs, des startups comme Hippocratic et OpenEvidence développent des modèles pour offrir des conseils pratiques aux cliniciens sur le terrain.
Mais à mesure que de nouveaux modèles adaptés aux cas d’utilisation médicale arrivent sur le marché, il devient de plus en plus difficile de savoir quels modèles – s’il y en a – fonctionnent comme annoncé. Comme les modèles médicaux sont souvent formés à partir de données provenant d’environnements cliniques limités et étroits (par exemple, les hôpitaux de la côte Est), certains présentent des biais à l’égard de certaines populations de patients, généralement des minorités, ce qui a des conséquences néfastes dans le monde réel.
Dans le but d’établir un moyen fiable et sûr de comparer et d’évaluer les modèles médicaux, MLCommons, le consortium d’ingénierie qui se concentre sur la construction d’outils pour les mesures de l’industrie de l’IA, a conçu une nouvelle plateforme de test appelée MedPerf. Selon MLCommons, MedPerf peut évaluer les modèles d’IA sur « diverses données médicales du monde réel » tout en protégeant la vie privée des patients.
« Notre objectif est d’utiliser l’analyse comparative comme outil pour améliorer l’IA médicale », a déclaré dans un communiqué de presse Alex Karargyris, coprésident du groupe de travail médical de MLCommons, qui est à l’origine de MedPerf. « Les tests neutres et scientifiques des modèles sur des ensembles de données vastes et diversifiés peuvent améliorer l’efficacité, réduire les biais, renforcer la confiance du public et soutenir la conformité réglementaire. »
MedPerf, fruit d’une collaboration de deux ans menée par le Medical Working Group, a été élaboré avec la participation de l’industrie et du monde universitaire – plus de 20 entreprises et plus de 20 institutions universitaires ont fait part de leurs commentaires, selon MLCommons. (Les membres du groupe de travail médical comprennent de grandes entreprises telles que Google, Amazon, IBM et Intel, ainsi que des universités telles que Brigham and Women’s Hospital, Stanford et MIT).
Contrairement aux suites d’évaluation comparative de l’IA à usage général de MLCommons, comme MLPerf, MedPerf est conçu pour être utilisé par les opérateurs et les clients des modèles médicaux – les organisations de soins de santé – plutôt que par les vendeurs. Les hôpitaux et les cliniques qui utilisent la plateforme MedPerf peuvent évaluer les modèles d’IA à la demande, en recourant à l' »évaluation fédérée » pour déployer des modèles à distance et les évaluer sur place.
MedPerf prend en charge les bibliothèques d’apprentissage automatique les plus courantes, en plus des modèles privés et des modèles disponibles uniquement via une API, comme ceux d’Epic et des services Azure OpenAI de Microsoft.
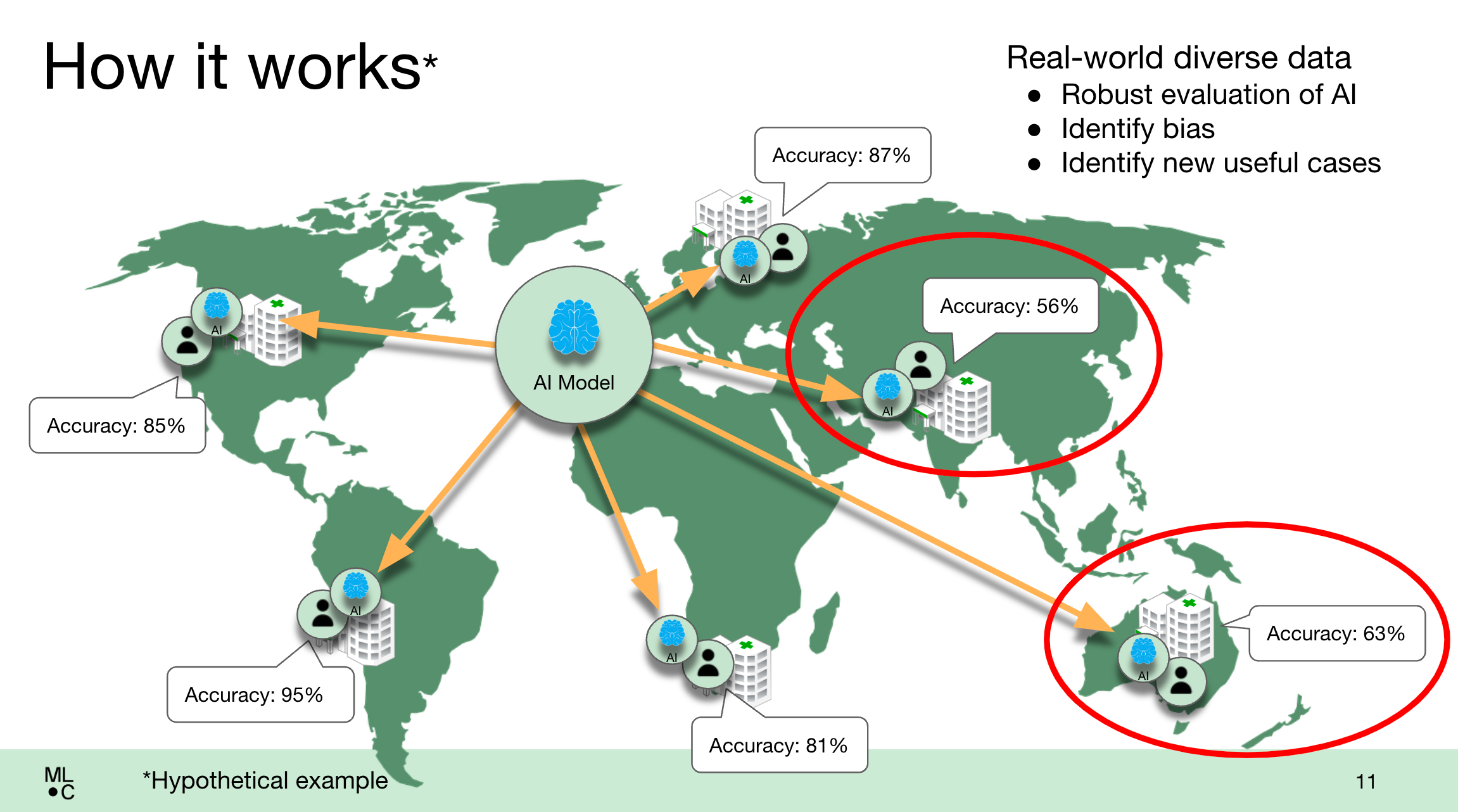
Illustration du fonctionnement pratique de la plateforme MedPerf.
Pour tester le système en début d’année, MedPerf a accueilli le Federated Tumor Segmentation (FeTS) Challenge financé par les NIH, une vaste comparaison de modèles pour évaluer le traitement post-opératoire du glioblastome (une tumeur cérébrale agressive). MedPerf a soutenu le test de 41 modèles différents cette année, fonctionnant à la fois sur site et dans le nuage, dans 32 sites de soins de santé sur six continents.
Selon MLCommons, tous les modèles ont montré des performances réduites dans des sites où les données démographiques des patients étaient différentes de celles sur lesquelles ils avaient été formés, révélant ainsi les biais qu’ils contenaient.
« Il est passionnant de voir les résultats des études pilotes de MedPerf sur l’IA médicale, où tous les modèles ont fonctionné sur les systèmes de l’hôpital, en s’appuyant sur des normes de données préétablies, sans partager aucune donnée », a déclaré Renato Umeton, directeur des opérations d’IA au Dana-Farber Cancer Institute et autre co-président du groupe de travail médical de MLCommons, dans un communiqué. « Les résultats renforcent le fait que les repères par le biais d’une évaluation fédérée sont un pas dans la bonne direction vers une médecine basée sur l’IA plus inclusive. »
MLCommons considère MedPerf, qui se limite pour l’instant à l’évaluation de modèles d’analyse de scans radiologiques, comme une « étape fondamentale » dans sa mission d’accélération de l’IA médicale grâce à des « approches ouvertes, neutres et scientifiques ». Il invite les chercheurs en IA à utiliser la plateforme pour valider leurs propres modèles dans les établissements de santé et les propriétaires de données à enregistrer les données de leurs patients afin d’accroître la robustesse des tests de MedPerf.
Mais cet auteur se demande si – en supposant que MedPerf fonctionne comme annoncé, ce qui n’est pas certain – la plateforme s’attaque vraiment aux problèmes insolubles de l’IA pour les soins de santé.
Un rapport récent et révélateur compilé par des chercheurs de l’université de Duke révèle un fossé énorme entre le marketing de l’IA et les mois – parfois les années – de travail nécessaire pour faire fonctionner la technologie de la bonne manière. Selon le rapport, la difficulté réside souvent dans la manière d’intégrer la technologie dans les routines quotidiennes des médecins et des infirmières, ainsi que dans les systèmes techniques et de prestation de soins compliqués qui les entourent.
Le problème n’est pas nouveau. En 2020, Google a publié un livre blanc d’une franchise surprenante qui expliquait les raisons pour lesquelles son outil de dépistage de la rétinopathie diabétique par l’IA n’avait pas été à la hauteur lors des tests en situation réelle. Les obstacles ne résidaient pas nécessairement dans les modèles, mais plutôt dans la manière dont les hôpitaux déployaient leur équipement, la force de la connectivité internet et même la manière dont les patients réagissaient à l’évaluation assistée par l’IA.
Sans surprise, les praticiens des soins de santé – et non les organisations – ont des sentiments mitigés à l’égard de l’IA dans les soins de santé. Selon un sondage réalisé par Yahoo Finance, 55 % d’entre eux estiment que la technologie n’est pas prête à être utilisée et seulement 26 % pensent qu’elle est fiable.
Cela ne veut pas dire que le biais des modèles médicaux n’est pas un problème réel – il l’est, et il a des conséquences. Il a été démontré que des systèmes tels que celui d’Epic pour l’identification des cas de septicémie, par exemple, passent à côté de nombreux cas de la maladie et émettent fréquemment de fausses alertes. Il est également vrai qu’il n’a pas été facile pour les organisations qui n’ont pas la taille de Google ou de Microsoft d’accéder à des données médicales diverses et actualisées en dehors des référentiels gratuits pour tester les modèles.
Mais il n’est pas judicieux d’accorder trop d’importance à une plateforme comme MedPerf lorsqu’il s’agit de la santé des personnes. Après tout, les critères de référence ne racontent qu’une partie de l’histoire. Le déploiement de modèles médicaux en toute sécurité nécessite un audit continu et approfondi de la part des fournisseurs et de leurs clients, sans parler des chercheurs. L’absence de tels tests n’est rien moins qu’irresponsable.