
La startup d’IA Hugging Face et ServiceNow Research, la division de recherche et développement de ServiceNow, ont lancé StarCoder, une alternative gratuite aux systèmes d’IA générateurs de code, sur le modèle de Copilot de GitHub.
Les systèmes de génération de code comme AlphaCode de DeepMind, CodeWhisperer d’Amazon et Codex d’OpenAI, qui alimente Copilot, donnent un aperçu alléchant de ce qui est possible avec l’IA dans le domaine de la programmation informatique. En supposant que les problèmes éthiques, techniques et juridiques soient un jour résolus (et que les outils de codage alimentés par l’IA ne provoquent pas plus de bogues et d’exploits de sécurité qu’ils n’en résolvent), ils pourraient réduire considérablement les coûts de développement tout en permettant aux codeurs de se concentrer sur des tâches plus créatives.
Selon une étude de l’université de Cambridge, au moins la moitié des efforts des développeurs sont consacrés au débogage et non à la programmation active, ce qui coûte à l’industrie du logiciel environ 312 milliards de dollars par an. Mais jusqu’à présent, seule une poignée de systèmes d’IA générateurs de code ont été mis gratuitement à la disposition du public, ce qui reflète les motivations commerciales des organisations qui les construisent (voir : Replit).
StarCoder, dont la licence permet une utilisation libre de droits par quiconque, y compris les entreprises, a été formé sur plus de 80 langages de programmation ainsi que sur des textes provenant de dépôts GitHub, y compris de la documentation et des carnets de programmation. StarCoder s’intègre à l’éditeur de code Visual Studio Code de Microsoft et, comme le ChatGPT d’OpenAI, peut suivre des instructions de base (par exemple, « créer une interface utilisateur ») et répondre à des questions sur le code.
Leandro von Werra, ingénieur en apprentissage automatique chez Hugging Face et co-dirigeant de StarCoder, affirme que StarCoder égale ou surpasse le modèle d’IA d’OpenAI utilisé pour les premières versions de Copilot.
« Une chose que nous avons apprise des versions telles que Stable Diffusion l’année dernière est la créativité et la capacité de la communauté open-source », a déclaré von Werra à TechCrunch lors d’une interview par e-mail. « Dans les semaines qui ont suivi la publication, la communauté a créé des dizaines de variantes du modèle ainsi que des applications personnalisées. La publication d’un puissant modèle de génération de code permet à chacun de l’affiner et de l’adapter à ses propres cas d’utilisation et permettra d’innombrables applications en aval. »
Construire un modèle
StarCoder fait partie du projet BigCode de Hugging Face et ServiceNow, qui compte plus de 600 personnes et a été lancé à la fin de l’année dernière, dans le but de développer des systèmes d’IA de pointe pour le code de manière « ouverte et responsable ». Hugging Face a fourni une grappe de calcul interne de 512 GPU Nvidia V100 pour entraîner le modèle StarCoder.
Divers groupes de travail BigCode se concentrent sur des sous-thèmes tels que la collecte d’ensembles de données, la mise en œuvre de méthodes d’entraînement de modèles de code, le développement d’une suite d’évaluation et la discussion des meilleures pratiques éthiques. Par exemple, le groupe de travail sur le droit, l’éthique et la gouvernance a étudié les questions relatives aux licences de données, à l’attribution du code généré au code original, à la rédaction d’informations personnelles identifiables (PII) et aux risques de production de codes malveillants.
Inspiré par les efforts antérieurs de Hugging Face pour ouvrir les systèmes sophistiqués de génération de texte, BigCode cherche à répondre à certaines des controverses soulevées par la pratique de la génération de code par l’IA. L’organisation à but non lucratif Software Freedom Conservancy, entre autres, a critiqué GitHub et OpenAI pour avoir utilisé du code source public, dont la totalité n’est pas sous licence permissive, pour former et monétiser Codex. Codex est disponible via les API payantes d’OpenAI et de Microsoft, tandis que GitHub a récemment commencé à facturer l’accès à Copilot.
Pour leur part, GitHub et OpenAI affirment que Codex et Copilot – protégés par la doctrine de l’usage loyal, du moins aux États-Unis – n’enfreignent aucun accord de licence.
« La publication d’un système capable de générer des codes peut servir de plateforme de recherche pour les institutions qui s’intéressent au sujet mais qui ne disposent pas des ressources ou du savoir-faire nécessaires pour former de tels modèles », a déclaré M. von Werra. « Nous pensons qu’à long terme, cela conduira à des recherches fructueuses sur la sécurité, les capacités et les limites des systèmes de génération de codes.
Contrairement à Copilot, StarCoder, qui compte 15 milliards de paramètres, a été entraîné pendant plusieurs jours sur un ensemble de données open source appelé The Stack, qui comprend plus de 19 millions de référentiels sous licence permissive et plus de six téraoctets de code dans plus de 350 langages de programmation. Dans l’apprentissage automatique, les paramètres sont les parties d’un système d’intelligence artificielle apprises à partir de données d’entraînement historiques et définissent essentiellement les compétences du système sur un problème, tel que la génération de code.
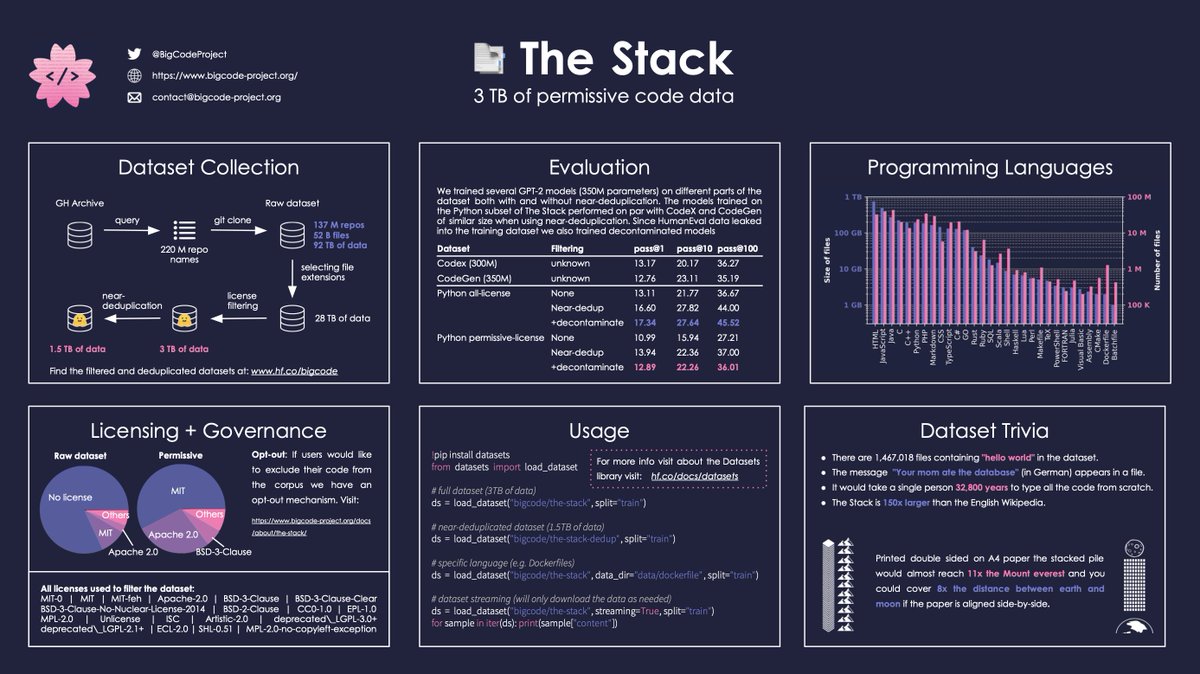
Un graphique décomposant le contenu de l’ensemble de données The Stack. Crédits d’image : BigCode
Parce qu’il fait l’objet d’une licence permissive, le code de The Stack peut être copié, modifié et redistribué. Mais le projet BigCode permet également aux développeurs de se retirer de The Stack, à l’instar des efforts déployés ailleurs pour permettre aux artistes de retirer leurs œuvres des ensembles de données d’entraînement à l’IA de type texte-image.
L’équipe BigCode s’est également efforcée de supprimer les IIP de The Stack, telles que les noms, les noms d’utilisateur, les adresses e-mail et IP, ainsi que les clés et les mots de passe. Ils ont créé un ensemble de données distinct de 12 000 fichiers contenant des IIP, qu’ils prévoient de mettre à la disposition des chercheurs par le biais d’un « accès réglementé ».
En outre, l’équipe BigCode a utilisé l’outil de détection des codes malveillants de Hugging Face pour supprimer les fichiers de The Stack qui pourraient être considérés comme « dangereux », tels que ceux contenant des exploits connus.
Les problèmes de confidentialité et de sécurité posés par les systèmes d’IA générative, qui sont pour la plupart formés à partir de données relativement non filtrées provenant du web, sont bien connus. ChatGPT a déjà fourni le numéro de téléphone d’un journaliste. Et GitHub a reconnu que Copilot pouvait générer des clés, des identifiants et des mots de passe vus dans ses données d’entraînement sur de nouvelles chaînes de caractères.
« Le code constitue l’une des propriétés intellectuelles les plus sensibles pour la plupart des entreprises », a déclaré M. von Werra. « En particulier, le fait de le partager en dehors de leur infrastructure pose d’immenses défis.
À cet égard, certains experts juridiques ont fait valoir que les systèmes d’IA générateurs de code pourraient mettre les entreprises en danger si elles incorporaient involontairement des textes protégés par le droit d’auteur ou des textes sensibles dans leurs logiciels de production. Comme le fait remarquer Elaine Atwell dans un article publié sur le blog d’entreprise de Kolide, étant donné que les systèmes tels que Copilot dépouillent le code de ses licences, il est difficile de savoir quel code peut être déployé et quel code peut avoir des conditions d’utilisation incompatibles.
En réponse aux critiques, GitHub a ajouté un bouton qui permet aux clients d’empêcher l’affichage du code suggéré qui correspond au contenu public de GitHub, potentiellement protégé par des droits d’auteur. Amazon a emboîté le pas en demandant à CodeWhisperer de mettre en évidence et éventuellement de filtrer la licence associée aux fonctions qu’il suggère et qui présentent une ressemblance avec les extraits trouvés dans ses données d’apprentissage.
Conducteurs professionnels
Qu’est-ce que ServiceNow, une société qui s’occupe principalement de logiciels d’automatisation d’entreprise, en retire ? Un « modèle performant et une licence de modèle d’IA responsable qui permet une utilisation commerciale », a déclaré Harm de Vries, directeur du Large Language Model Lab chez ServiceNow Research et co-directeur du projet BigCode.
On imagine que ServiceNow finira par intégrer StarCoder dans ses produits commerciaux. La société n’a pas voulu révéler le montant, en dollars, qu’elle a investi dans le projet BigCode, si ce n’est que la quantité de calcul donnée était « substantielle ».
« Le Large Language Models Lab de ServiceNow Research développe une expertise sur le développement responsable de modèles d’IA génératifs afin de garantir le déploiement sûr et éthique de ces modèles puissants pour nos clients », a déclaré M. de Vries. « L’approche de recherche scientifique ouverte de BigCode offre aux développeurs et aux clients de ServiceNow une transparence totale sur la façon dont tout a été développé et démontre l’engagement de ServiceNow à apporter des contributions socialement responsables à la communauté. »
StarCoder n’est pas open source au sens strict du terme. Il est plutôt publié sous un régime de licence, OpenRAIL-M, qui comprend des restrictions de cas d’utilisation « légalement applicables » auxquelles les dérivés du modèle – et les applications utilisant le modèle – doivent se conformer.
Par exemple, les utilisateurs de StarCoder doivent s’engager à ne pas utiliser le modèle pour générer ou distribuer du code malveillant. Bien que les exemples réels soient peu nombreux (du moins pour l’instant), les chercheurs ont démontré comment l’IA comme StarCoder pouvait être utilisée dans les logiciels malveillants pour échapper aux formes de base de la détection.
Reste à savoir si les développeurs respectent réellement les termes de la licence. Les menaces juridiques mises à part, il n’y a rien au niveau technique de base qui les empêche d’ignorer les termes à leurs propres fins.
C’est ce qui s’est passé avec Stable Diffusion, dont la licence restrictive a été ignorée par des développeurs qui ont utilisé le modèle d’IA générative pour créer des images de deepfakes de célébrités.
Mais cette possibilité n’a pas découragé von Werra, qui estime que les inconvénients de ne pas publier StarCoder ne sont pas compensés par les avantages.
« Au lancement, StarCoder n’offrira pas autant de fonctionnalités que GitHub Copilot, mais grâce à sa nature open-source, la communauté peut l’améliorer en cours de route et intégrer des modèles personnalisés », a-t-il déclaré.
Les référentiels de code de StarCoder, le cadre d’apprentissage des modèles, les méthodes de filtrage des ensembles de données, la suite d’évaluation des codes et les carnets d’analyse de la recherche sont disponibles sur GitHub depuis cette semaine. Le projet BigCode en assurera la maintenance à l’avenir, les groupes cherchant à développer des modèles de génération de code plus performants, alimentés par les contributions de la communauté.
Il y a certainement du travail à faire. Dans le document technique accompagnant la publication de StarCoder, Hugging Face et ServiceNow indiquent que le modèle peut produire un contenu inexact, offensant et trompeur, ainsi que des informations confidentielles et des codes malveillants qui ont réussi à passer l’étape du filtrage des ensembles de données.