
Suivre l’évolution d’un secteur aussi rapide que l’IA n’est pas une mince affaire. En attendant qu’une IA puisse le faire à votre place, voici un récapitulatif pratique des événements récents dans le monde de l’apprentissage automatique, ainsi que des recherches et expériences notables que nous n’avons pas couvertes par elles-mêmes.
La semaine dernière, Midjourney, la startup spécialisée dans l’IA qui crée des générateurs d’images (et bientôt de vidéos), a apporté une petite modification à ses conditions d’utilisation concernant sa politique en matière de litiges de propriété intellectuelle. Il s’agit principalement de remplacer le langage humoristique par des clauses plus juridiques, sans doute fondées sur la jurisprudence. Mais ce changement peut également être considéré comme un signe de la conviction de Midjourney que les fournisseurs d’IA comme elle sortiront vainqueurs des batailles judiciaires avec les créateurs dont les œuvres constituent les données d’entraînement des fournisseurs.

La modification des conditions d’utilisation de Midjourney.
Les modèles d’IA générative tels que celui de Midjourney sont formés sur un très grand nombre d’exemples – par exemple des images et des textes – provenant généralement de sites web publics et de référentiels sur le web. Les fournisseurs affirment que l’usage loyal, la doctrine juridique qui autorise l’utilisation d’œuvres protégées par le droit d’auteur pour réaliser une création secondaire à condition qu’elle soit transformatrice, les protège en ce qui concerne la formation aux modèles. Mais tous les créateurs ne sont pas d’accord, en particulier à la lumière d’un nombre croissant d’études montrant que les modèles peuvent « régurgiter » des données d’entraînement, et le font.
Certains fournisseurs ont adopté une approche proactive, en concluant des accords de licence avec les créateurs de contenu et en mettant en place des systèmes d’exclusion pour les ensembles de données d’entraînement. D’autres ont promis que, si les clients sont impliqués dans un procès sur les droits d’auteur découlant de leur utilisation des outils GenAI d’un fournisseur, ils ne seront pas tenus de payer les frais de justice.
Midjourney ne fait pas partie des entreprises proactives.
Au contraire, Midjourney a fait preuve d’une certaine effronterie dans son utilisation d’œuvres protégées par le droit d’auteur, en tenant à un moment donné une liste de milliers d’artistes – y compris des illustrateurs et des concepteurs de grandes marques comme Hasbro et Nintendo – dont les œuvres étaient ou allaient être utilisées pour entraîner les modèles de Midjourney. Une étude montre de manière convaincante que Midjourney a également utilisé des émissions de télévision et des films dans ses données d’entraînement, de « Toy Story » à « Star Wars » en passant par « Dune » et « Avengers ».
Il existe un scénario dans lequel les décisions du tribunal donneraient raison à Midjourney. Si le système judiciaire décide que l’utilisation équitable s’applique, rien n’empêche la startup de continuer comme elle l’a fait jusqu’à présent, en récupérant des données protégées par le droit d’auteur, anciennes et nouvelles, et en s’entraînant à partir de ces données.
Mais cela semble être un pari risqué.
Midjourney vole de ses propres ailes en ce moment, et aurait atteint un chiffre d’affaires d’environ 200 millions de dollars sans avoir reçu le moindre investissement extérieur. Mais les avocats coûtent cher. Et s’il est décidé que l’utilisation équitable ne s’applique pas dans le cas de Midjourney, la société serait décimée du jour au lendemain.
Il n’y a pas de récompense sans risque, n’est-ce pas ?
Voici d’autres articles sur l’IA parus ces derniers jours :
Une publicité assistée par l’IA attire le mauvais type d’attention: Des créateurs sur Instagram se sont emportés contre un réalisateur dont la publicité réutilisait le travail d’un autre (beaucoup plus difficile et impressionnant) sans le créditer.
Les autorités de l’UE mettent en garde les plateformes d’IA à l’approche des élections: Elles demandent aux plus grandes entreprises du secteur de la technologie d’expliquer leur approche en matière de prévention des fraudes électorales.
Google Deepmind veut que votre partenaire de jeu coopératif devienne son IA: L’entraînement d’un agent sur de nombreuses heures de jeu en 3D l’a rendu capable d’effectuer des tâches simples formulées en langage naturel.
Le problème des critères de référence : De très nombreux fournisseurs de solutions d’intelligence artificielle affirment que leurs modèles sont à la hauteur de la concurrence ou qu’ils la battent selon des critères objectifs. Mais les mesures qu’ils utilisent sont souvent erronées.
AI2 obtient 200 millions de dollars : L’incubateur AI2, issu de l’institut à but non lucratif Allen Institute for AI, a obtenu une manne de 200 millions de dollars en calcul dont les startups participant à son programme peuvent tirer parti pour accélérer leur développement.
L’Inde exige l’approbation du gouvernement pour l’IA, puis revient en arrière : Le gouvernement indien ne semble pas pouvoir décider du niveau de réglementation approprié pour l’industrie de l’IA.
Anthropic lance de nouveaux modèles : La startup d’IA Anthropic a lancé une nouvelle famille de modèles, Claude 3, qui, selon elle, rivalise avec le GPT-4 d’OpenAI. Nous avons testé le modèle phare (Claude 3 Opus) et l’avons trouvé impressionnant, mais aussi insuffisant dans des domaines tels que l’actualité.
Les deepfakes politiques : Une étude du Center for Countering Digital Hate (CCDH), une organisation britannique à but non lucratif, se penche sur le volume croissant de désinformation générée par l’IA – en particulier les images de deepfake relatives aux élections – sur X (anciennement Twitter) au cours de l’année écoulée.
OpenAI contre Musk : OpenAI déclare qu’elle a l’intention de rejeter toutes les plaintes déposées par le PDG de X, Elon Musk, dans un récent procès, et suggère que l’entrepreneur milliardaire – qui a participé à la cofondation de l’entreprise – n’a pas vraiment eu d’impact sur le développement et le succès d’OpenAI.
Révision de Rufus : Le mois dernier, Amazon a annoncé le lancement d’un nouveau chatbot doté d’une intelligence artificielle, Rufus, dans l’application Amazon Shopping pour Android et iOS. Nous avons eu un accès anticipé – et avons été rapidement déçus par le manque de choses que Rufus peut faire (et bien faire).
Plus d’informations sur l’apprentissage automatique
Molécules ! Comment fonctionnent-elles ? Les modèles d’IA nous ont aidés à comprendre et à prédire la dynamique moléculaire, la conformation et d’autres aspects du monde nanoscopique qui, autrement, nécessiteraient des méthodes coûteuses et complexes pour être testés. Il faut toujours vérifier, bien sûr, mais des choses comme AlphaFold changent rapidement la donne.
Microsoft propose un nouveau modèle appelé ViSNet, qui vise à prédire ce que l’on appelle les relations structure-activité, c’est-à-dire les relations complexes entre les molécules et l’activité biologique. Il s’agit d’un modèle encore expérimental et réservé aux chercheurs, mais il est toujours agréable de voir des problèmes de sciences exactes abordés par des moyens technologiques de pointe.
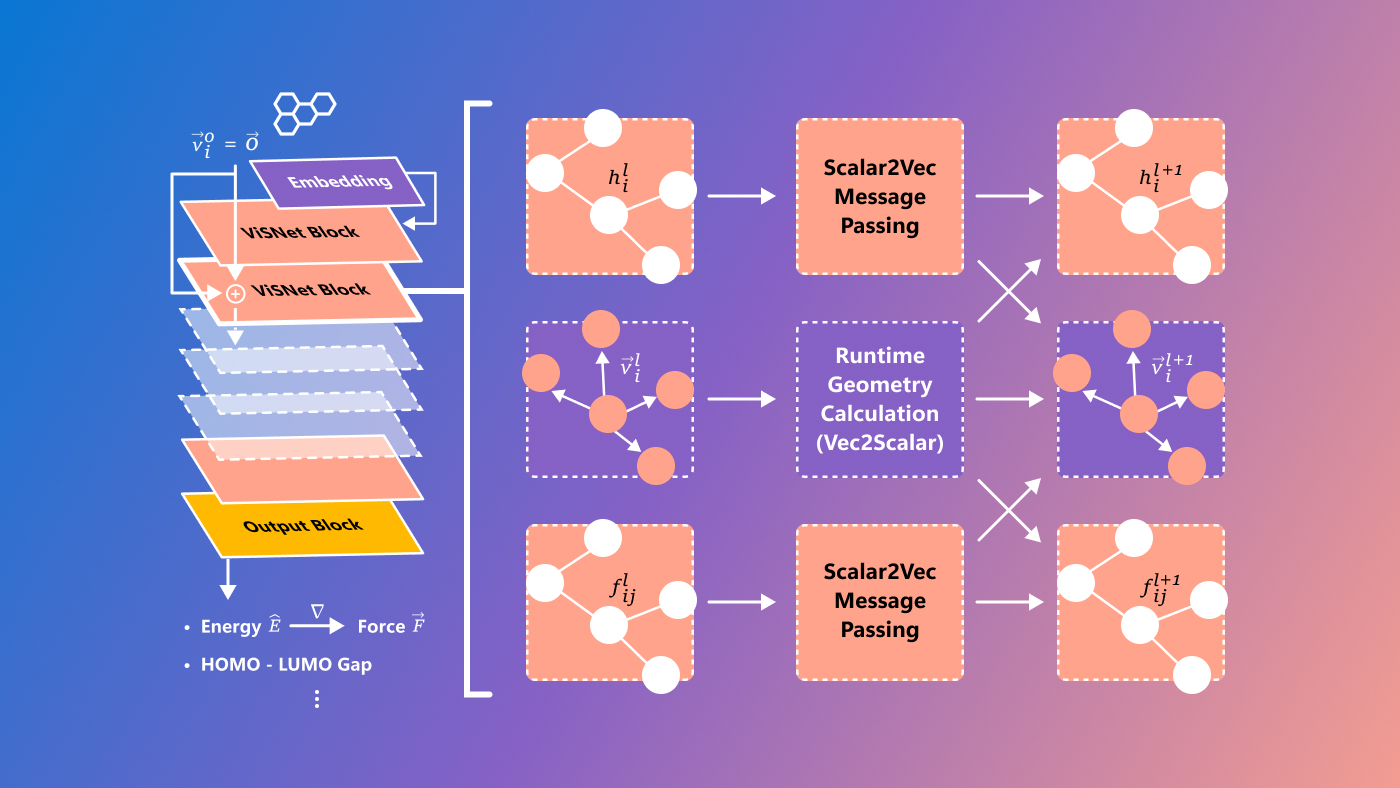
Crédits d’image : Microsoft
Les chercheurs de l’université de Manchester cherchent spécifiquement à identifier et à prédire les variantes de COVID-19, moins à partir d’une structure pure comme ViSNet que par l’analyse des très vastes ensembles de données génétiques relatives à l’évolution des coronavirus.
« La quantité sans précédent de données génétiques générées pendant la pandémie exige que nous améliorions nos méthodes pour les analyser en profondeur », a déclaré le chercheur principal Thomas House. Son collègue Roberto Cahuantzi a ajouté : « Notre analyse sert de preuve de concept, démontrant l’utilisation potentielle des méthodes d’apprentissage automatique comme outil d’alerte pour la découverte précoce de variantes majeures émergentes. »
L’IA peut également concevoir des molécules, et un certain nombre de chercheurs ont signé une initiative appelant à la sécurité et à l’éthique dans ce domaine. Cependant, comme le fait remarquer David Baker (l’un des biophysiciens computationnels les plus éminents au monde), « les avantages potentiels de la conception de protéines dépassent largement les dangers à ce stade ». En tant que concepteur de protéines d’IA, il serait dire cela. Mais nous devons tout de même nous méfier d’une réglementation qui passe à côté de l’essentiel et qui entrave la recherche légitime tout en permettant aux mauvais acteurs de jouir de la liberté.
Des spécialistes de l’atmosphère de l’université de Washington ont formulé une affirmation intéressante sur la base d’une analyse de l’IA de 25 années d’imagerie satellitaire au-dessus du Turkménistan. En substance, l’idée reçue selon laquelle les bouleversements économiques qui ont suivi la chute de l’Union soviétique ont entraîné une réduction des émissions n’est peut-être pas vraie – en fait, c’est plutôt l’inverse qui s’est produit.
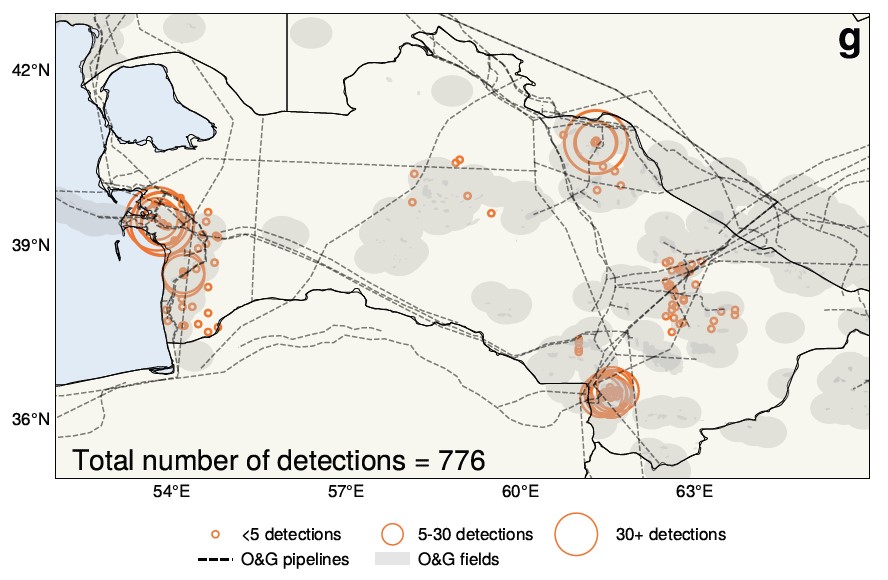
AI a contribué à trouver et à mesurer les fuites de méthane présentées ici.
« Nous constatons que l’effondrement de l’Union soviétique semble entraîner, de manière surprenante, une augmentation des émissions de méthane », a déclaré Alex Turner, professeur à l’université de Washington. Les vastes ensembles de données et le manque de temps pour les passer au crible ont fait de ce sujet une cible naturelle pour l’IA, qui a abouti à ce renversement inattendu.
Les grands modèles de langage sont largement formés sur des données sources en anglais, mais cela peut avoir une incidence sur d’autres langues. Des chercheurs de l’EPFL qui ont étudié le « langage latent » de LlaMa-2 ont constaté que le modèle semble revenir à l’anglais en interne, même lorsqu’il traduit entre le français et le chinois. Les chercheurs suggèrent toutefois qu’il ne s’agit pas seulement d’un processus de traduction paresseux, mais que le modèle a en fait structuré tout son espace conceptuel latent autour de notions et de représentations anglaises. Est-ce important ? Probablement. Nous devrions de toute façon diversifier nos ensembles de données.