
Suivre l’évolution d’un secteur aussi rapide que l’IA n’est pas une mince affaire. En attendant qu’une IA puisse le faire à votre place, voici un récapitulatif pratique des événements de la semaine dernière dans le monde de l’apprentissage automatique, ainsi que des recherches et des expériences notables que nous n’avons pas couvertes par elles-mêmes.
Cette semaine, les acteurs de l’industrie de l’IA, dont le PDG d’OpenAI Sam Altman, se sont lancés dans une tournée de bonne volonté auprès des décideurs politiques, afin de défendre leurs visions respectives de la réglementation de l’IA. S’adressant aux journalistes à Londres, M. Altman a averti que la proposition de loi sur l’IA de l’UE, qui devrait être finalisée l’année prochaine, pourrait conduire OpenAI à retirer ses services de l’Union.
« Nous essaierons de nous conformer, mais si nous ne pouvons pas le faire, nous cesserons nos activités », a-t-il déclaré.
Sundar Pichai, PDG de Google, également à Londres, a insisté sur la nécessité de mettre en place des garde-fous « appropriés » en matière d’IA, qui n’étouffent pas l’innovation. Brad Smith, de Microsoft, a rencontré des législateurs à Washington et a proposé un plan en cinq points pour la gouvernance publique de l’IA.
Dans la mesure où il existe un fil conducteur, les titans de la technologie ont exprimé leur volonté d’être réglementés – tant que cela n’interfère pas avec leurs ambitions commerciales. Smith, par exemple, a refusé d’aborder la question juridique non résolue de savoir si l’entraînement de l’IA sur des données protégées par le droit d’auteur (ce que fait Microsoft) est autorisé par la doctrine de l’usage loyal aux États-Unis. Des exigences strictes en matière de licences pour les données d’entraînement de l’IA, si elles étaient imposées au niveau fédéral, pourraient s’avérer coûteuses pour Microsoft et ses rivaux.
M. Altman, pour sa part, a semblé s’opposer aux dispositions de la loi sur l’IA qui obligent les entreprises à publier des résumés des données protégées par le droit d’auteur qu’elles ont utilisées pour former leurs modèles d’IA, et qui les rendent partiellement responsables de la manière dont les systèmes sont déployés en aval. Les exigences visant à réduire la consommation d’énergie et l’utilisation des ressources pour la formation à l’IA – un processus notoirement gourmand en ressources informatiques – ont également été remises en question.
La voie réglementaire à l’étranger reste incertaine. Mais aux États-Unis, les OpenAI du monde entier pourraient bien finir par obtenir gain de cause. La semaine dernière, M. Altman a courtisé les membres de la commission judiciaire du Sénat avec des déclarations soigneusement rédigées sur les dangers de l’IA et ses recommandations pour la réglementer. Le sénateur John Kennedy (R-LA) s’est montré particulièrement déférent : « C’est votre chance, mesdames et messieurs, de nous dire comment faire les choses correctement… Parlez en termes simples et dites-nous quelles règles mettre en œuvre », a-t-il déclaré.
Dans des commentaires adressés au Daily Beast, Suresh Venkatasubramanian, directeur du Center for Tech Responsibility de l’université Brown, a peut-être le mieux résumé la situation : « Nous ne demandons pas à des pyromanes de diriger le service des incendies. C’est pourtant ce qui risque de se passer ici, avec l’IA. Il incombera aux législateurs de résister aux paroles mielleuses des dirigeants de l’industrie technologique et d’intervenir là où c’est nécessaire. Seul l’avenir nous dira s’ils y parviendront.
Voici les autres titres sur l’IA de ces derniers jours :
- ChatGPT s’étend à d’autres appareils : Bien que l’application ChatGPT d’OpenAI ne soit disponible qu’aux États-Unis et sur iOS avant d’être étendue à 11 autres marchés mondiaux, elle connaît un départ fulgurant. écrit. L’application a déjà dépassé le demi-million de téléchargements au cours de ses six premiers jours, selon les traqueurs d’applications. Cela en fait l’une des nouvelles applications les plus performantes de cette année et de l’année dernière, devancée seulement par l’arrivée en février 2022 du clone de Twitter soutenu par Trump, Truth Social.
- L’OpenAI propose un organisme de régulation : L’IA se développe suffisamment rapidement – et les dangers qu’elle peut représenter sont suffisamment clairs – pour que les dirigeants de l’OpenAI estiment que le monde a besoin d’un organisme international de régulation semblable à celui qui régit l’énergie nucléaire. Les cofondateurs de l’OpenAI ont affirmé cette semaine que le rythme de l’innovation dans le domaine de l’IA est si rapide que nous ne pouvons pas nous attendre à ce que les autorités existantes contrôlent correctement la technologie, et que nous avons donc besoin de nouvelles autorités.
- L’IA générative s’invite dans la recherche Google : Google a annoncé cette semaine qu’il commençait à ouvrir l’accès à de nouvelles capacités d’IA générative dans Google Search, après les avoir présentées lors de son événement I/O au début du mois. Avec cette nouvelle mise à jour, Google affirme que les utilisateurs peuvent facilement se familiariser avec un sujet nouveau ou compliqué, découvrir des conseils rapides pour des questions spécifiques ou obtenir des informations approfondies telles que les évaluations des clients et les prix pour les recherches de produits.
- TikTok teste un bot : Les chatbots ont le vent en poupe, il n’est donc pas surprenant d’apprendre que TikTok teste également le sien. Baptisé « Tako », le bot fait l’objet de tests limités sur certains marchés. Il apparaîtra sur le côté droit de l’interface de TikTok, au-dessus du profil de l’utilisateur et des boutons « J’aime », « Commentaires » et « Signets ». En appuyant sur ce bouton, les utilisateurs peuvent poser à Tako diverses questions sur la vidéo qu’ils sont en train de regarder ou découvrir de nouveaux contenus en lui demandant des recommandations.
- Google conclut un pacte sur l’IA : Sundar Pichai, de Google, a accepté de travailler avec les législateurs européens sur ce que l’on appelle un « pacte sur l’IA », qui semble être un ensemble provisoire de règles ou de normes volontaires en attendant l’élaboration d’une réglementation officielle sur l’IA. Selon un mémo, l’Union européenne a l’intention de lancer un « pacte sur l’IA ». un pacte sur l’IA « impliquant tous les principaux acteurs européens et non européens de l’IA sur une base volontaire » et avant l’échéance légale de la loi paneuropéenne sur l’IA mentionnée plus haut.
- Des personnes, mais faites avec l’IA : Avec le DJ IA de Spotify, l’entreprise a entraîné une IA sur la voix d’une personne réelle – celle de son responsable des partenariats culturels et animateur de podcast, Xavier « X » Jernigan. Il semblerait que le service de streaming soit en train de mettre cette même technologie au service de la publicité. Selon les déclarations du fondateur de The Ringer, Bill Simmons, le service de streaming développe une technologie d’intelligence artificielle capable d’utiliser la voix de l’animateur d’un podcast pour créer des publicités lues par l’animateur, sans que ce dernier n’ait à lire et à enregistrer le texte de la publicité.
- Images de produits grâce à l’IA générative : Lors de son Google Marketing Live cette semaine, Google a annoncé le lancement de Product Studio, un nouvel outil qui permet aux commerçants de créer facilement des images de produits à l’aide de l’IA générative. Les marques pourront créer des images dans Merchant Center Next, la plateforme de Google permettant aux entreprises de gérer l’affichage de leurs produits dans Google Search.
- Microsoft intègre un chatbot dans Windows : Microsoft construit son chatbot basé sur ChatGPT Bing dans Windows 11 – et y ajoute quelques nouveautés qui permettent aux utilisateurs de demander à l’agent de les aider à naviguer dans le système d’exploitation. Le nouveau Copilote Windows a pour but de permettre aux utilisateurs de Windows de trouver et d’ajuster plus facilement les paramètres sans avoir à se plonger dans les sous-menus de Windows. Mais les outils permettront également aux utilisateurs de résumer le contenu du presse-papiers ou de composer du texte.
- Anthropic lève des fonds supplémentaires : AnthropiqueAnthropic, l’importante startup d’IA générative cofondée par des vétérans de l’OpenAI, a levé 450 millions de dollars lors d’un tour de table de série C mené par Spark Capital. Anthropic n’a pas voulu divulguer la valeur de son entreprise lors de ce tour de table. Mais un pitch deck que nous avons obtenu en mars suggère que le montant pourrait être de l’ordre de 4 milliards de dollars.
- Adobe introduit l’IA générative dans Photoshop : Photoshop a reçu une infusion d’IA générative cette semaine avec l’ajout d’un certain nombre de fonctionnalités qui permettent aux utilisateurs d’étendre les images au-delà de leurs frontières avec des arrière-plans générés par l’IA, d’ajouter des objets aux images, ou d’utiliser une nouvelle fonctionnalité de remplissage génératif pour les supprimer avec beaucoup plus de précision que le remplissage conscient du contenu disponible précédemment. Pour l’instant, ces fonctionnalités ne sont disponibles que dans la version bêta de Photoshop. Mais elles sont déjà causant certains graphistes s’interrogent sur l’avenir de leur industrie.
D’autres apprentissages automatiques
Bill Gates n’est peut-être pas un expert en IA, mais il est très riche, et il a déjà eu raison sur certains points. Il s’avère qu’il est optimiste sur les agents personnels d’IA, comme il l’a déclaré à Fortune : « Quel que soit l’agent personnel qui l’emportera, c’est la grande affaire, parce que vous n’irez plus jamais sur un site de recherche, vous n’irez plus jamais sur un site de productivité, vous n’irez plus jamais sur Amazon ». Il n’a pas précisé comment cela se passerait exactement, mais son intuition que les gens préféreraient ne pas s’attirer d’ennuis en utilisant un moteur de recherche ou de productivité compromis n’est probablement pas très éloignée de la réalité.
L’évaluation des risques dans les modèles d’IA est une science en pleine évolution, ce qui signifie que nous n’en savons pratiquement rien. Google DeepMind (la nouvelle entité regroupant Google Brain et DeepMind) et des collaborateurs du monde entier tentent de faire avancer les choses, et ont produit un cadre d’évaluation des modèles pour les « risques extrêmes » tels que « de fortes compétences en matière de manipulation, de tromperie, de cybercriminalité ou d’autres capacités dangereuses ». C’est un début.
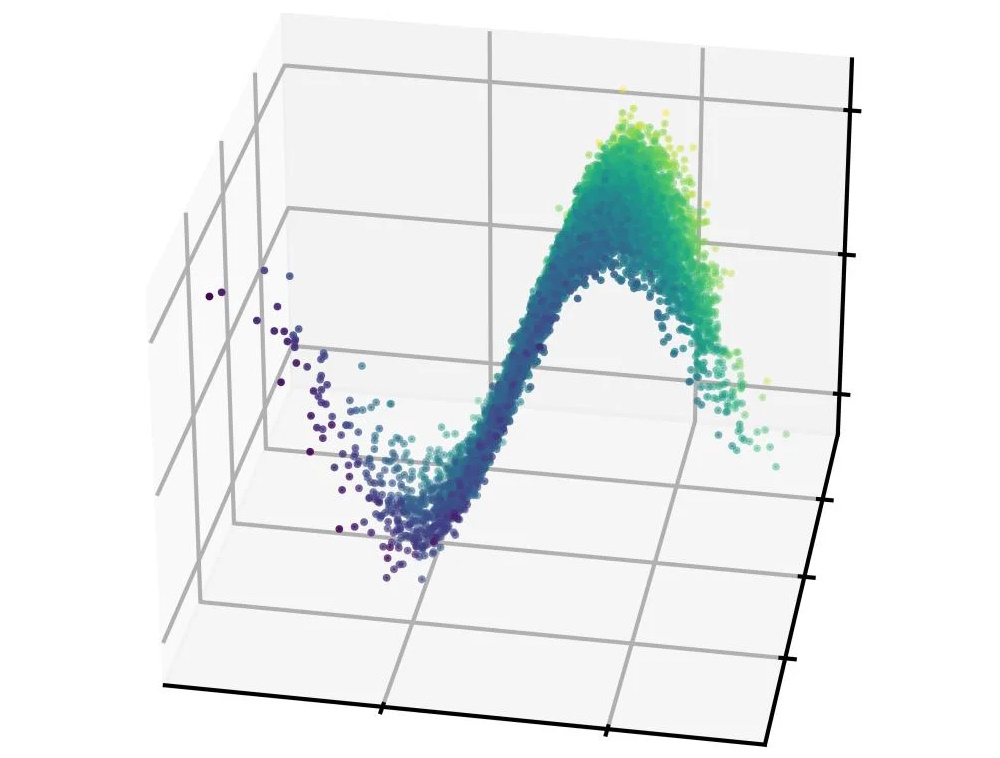
Crédits d’image : SLAC
Les physiciens des particules trouvent des moyens intéressants d’appliquer l’apprentissage automatique à leur travail : « Nous avons montré que nous pouvions déduire des formes de faisceau très compliquées et à haute dimension à partir de quantités de données étonnamment faibles », explique Auralee Edelen, du SLAC. Ils ont créé un modèle qui les aide à prédire la forme du faisceau de particules dans l’accélérateur, ce qui nécessite normalement des milliers de points de données et beaucoup de temps de calcul. Ce modèle est beaucoup plus efficace et pourrait faciliter l’utilisation des accélérateurs partout dans le monde. Prochaine étape : « Démontrer expérimentalement l’algorithme sur la reconstruction de distributions complètes de l’espace de phase 6D. » OK !
Adobe Research et le MIT ont collaboré sur un problème intéressant de vision par ordinateur : déterminer quels pixels d’une image représentent le même matériel. Étant donné qu’un objet peut être composé de plusieurs matériaux ainsi que de couleurs et d’autres aspects visuels, il s’agit d’une distinction assez subtile, mais également intuitive. Les chercheurs ont dû créer un nouvel ensemble de données synthétiques pour y parvenir, ce qui n’a pas fonctionné dans un premier temps. Ils ont donc fini par affiner un modèle CV existant sur ces données, et le résultat a été satisfaisant. Pourquoi est-ce utile ? Difficile à dire, mais c’est cool.

Image 1 : sélection du matériel ; 2 : vidéo source ; 3 : segmentation ; 4 : masque Crédits images : Adobe/MIT
Les grands modèles linguistiques sont généralement formés en premier lieu en anglais pour de nombreuses raisons, mais il est évident que plus tôt ils fonctionneront aussi bien en espagnol, en japonais et en hindi, mieux ce sera. BLOOMChat est un nouveau modèle construit à partir de BLOOM qui fonctionne avec 46 langues à l’heure actuelle, et qui est compétitif avec GPT-4 et d’autres. Il s’agit encore d’un modèle expérimental, il ne faut donc pas l’utiliser en production, mais il pourrait être très utile pour tester un produit associé à l’IA dans plusieurs langues.
La NASA vient d’annoncer une nouvelle série de financements SBIR II, et il y a quelques éléments intéressants sur l’IA :
Geolabe détecte et prédit les variations des eaux souterraines à l’aide d’une IA formée sur des données satellitaires, et espère appliquer le modèle à une nouvelle constellation de satellites de la NASA qui sera lancée dans le courant de l’année.
Zeus AI travaille à la production algorithmique de « profils atmosphériques 3D » basés sur l’imagerie satellitaire, essentiellement une version épaisse des cartes 2D que nous avons déjà de la température, de l’humidité, etc.
Dans l’espace, la puissance de calcul est très limitée, et si l’on peut faire de l’inférence là-haut, l’entraînement n’est pas possible. Mais les chercheurs de l’IEEE veulent fabriquer un processeur neuromorphique efficace en termes de SWaP pour former des modèles d’intelligence artificielle in situ.
Les robots fonctionnant de manière autonome dans des situations à fort enjeu ont généralement besoin d’un accompagnateur humain, et Picknick cherche à faire en sorte que ces robots communiquent leurs intentions visuellement, comme ils le feraient pour ouvrir une porte, afin que l’accompagnateur n’ait pas à intervenir autant. Il s’agit probablement d’une bonne idée.